索引是什么
索引是一种能够改变操作速度的特殊数据结构,索引的表达形式有很多种,生活中有很多用到索引的地方,我们举几个例子来理解:
- 图书馆书目标签:给每一本书建立唯一的编号,将编号和书架位置做好一一映射,这样我们就可以通过"类型-编号"快速的找到我们想要的书;有的同学可能会说:我们在查找的时候都是通过书的名字去查询的,没有用书的编号去查询啊,但也能查出来,这又是为啥?艾玛~这不就是书名和编号又做了一对多映射了么(因为书名重复的时候会有多个编号,所以用一对多),我们可以先通过书名找出书的编号,然后再根据编号找到书在书架的位置,然后一锤定音(了解过MySQL索引的这时候是不是立刻想到了回表这个词)。这里书编号、书名就是图书馆书目的索引
- 词典:我们这里说一下汉语词典,我们可以按拼音、笔画、偏旁部首等排序的目录快速查找到需要的字。这里拼音、笔画、偏旁部首等就是词典的索引
- 酒店房卡:我们住酒店的时候,如果自助办完手续后,自助机吐出给我们一张房卡,然后如果房卡上没有门牌号的话,我们需要挨个儿房间的去尝试,酒店要是有几百个房间且我们正巧是最后一个房间的话,那估计等找到房子已经该要退房了,哈哈~所以房卡上直接告诉了我们房号,我们可以根据房号直接找到我们要入住的房间。这里房间号就是酒店房间的索引。
通过上面的例子,相信一定能理解索引是什么、作用是什么了吧,我们来总结一下:索引是标识一个物体/数据的特殊属性,这个属性可能是唯一的,也可能不是唯一的,可以是一个属性作索引,也可以是多个属性一起作索引。
索引有什么用
索引的作用是什么,我们为什么要用索引?
相信很多人都会有这个问题,其实在数据量很小的情况下,比如一眼就看得到所有数据,那就没必要用索引了,为什么没必要?因为本来数据量就少,如果创建了索引的话,我们每次还要去查索引,然后从索引再去查具体数据,是不是很麻烦?并且有新数据插入或者索引的数据变更的时候,还需要同步去修改索引的数值,不然就会造成索引出现脏数据和数据无对应的索引等情况;若不建立索引的话,遍历所有的数据去查询某一条或者某几条出来,耗时貌似也不大,并且还不用在修改插入数据的时候也不用耗时去维护索引。
但是在数据量较大的情况下,我们就必须要建立索引了,因为如果我们为了查找一条数据而要去遍历几十万条数据的话,耗时是相当大的,特别是如果恰巧我们要查的数据在倒数第一条,那就彻底崩溃了,所以我们需要为数据集依据查询条目建立索引,我们先根据条件查询出来索引,然后把索引指向的存储位置上的数据捞出来直接返回就行了,是不是很方便?当然插入更新数据引起的索引更新相对于无索引查询带来的消耗来说,微乎其微。
聊到这里,肯定有一个疑问:我们在查询索引时不一样是要遍历所有的索引吗?这和遍历数据集中的所有数据有什么区别?
索引结构
为了解决索引的快速查询和命中,我们有哈希和树两种结构,在不同的MySQL存储引擎中支持的索引结构不同,比如MyIsam支持Hash,InnoDB支持树,并且是B+树,当然也知道Hash,但是属于是变形的Hash,和MyIsam中的不同,且Hash索引的创建和维护完全由MySQL自己决定,只有在数据量达到一定数量的时候才会创建Hash,但是使用Hash结构也是有缺陷的:
Hash结构索引
-
优势
Hash索引实际上就是采用一定的Hash算法,把键值转换成哈希值,检索的时候不需要像树那样从根开始找起,能够根据哈希值一次性定位到位置,所以在哈希冲突不严重的情况下,检索效率远高于树
-
缺陷
- 只能匹配是否相等,不能实现范围查找,只能用于=、IN和<>
- 无法使用Order By进行排序
- 组合索引的时候,无法实现最左匹配,因为组合索引会将所有的字段整合一起做Hash计算,所以如果仅部分索引字段进行Hash计算的话,可能匹配到其他数据
- 当数据量越来越大的时候,哈希冲突会越来越严重,性能会下降的很严重
-
结构图

树结构
树有多种,MySQL中使用的是B+树,这是由B树演变而来的,B树又是从AVL树演变而来,我们分别来看一下各种树的结构和检索方式,然后推导出为什么MySQL使用B+树。
-
AVL树
-
结构

-
特征
在AVL树中,任一节点对应的两棵子树的最大高度差为1,因此它也被称为高度平衡树。查找、插入和删除在平均和最坏情况下的时间复杂度都是O(log n)。增加和删除元素的操作则可能需要借由一次或多次树旋转,以实现树的重新平衡
-
作为索引
- 每个节点均能存储数据
- 每一个节点都需要进行一次磁盘IO
- 由于每一个节点最多只能有两个子节点,所以在数据量大的时候,树的高度会很大
-
-
B树 (B-树)
-
结构

-
特征
B树,概括来说是一个一般化的二叉查找树(binary search tree)一个节点可以拥有2个以上的子节点。与自平衡二叉查找树不同,B树适用于读写相对大的数据块的存储系统,例如磁盘。B树减少定位记录时所经历的中间过程,从而加快存取速度。B树这种数据结构可以用来描述外部存储。这种数据结构常被应用在数据库和文件系统的实现上。
-
作为索引
- 解决AVL树每个节点只能存储一个数据的问题
- 减少AVL树查询过程中的IO次数
-
-
B+树
-
结构
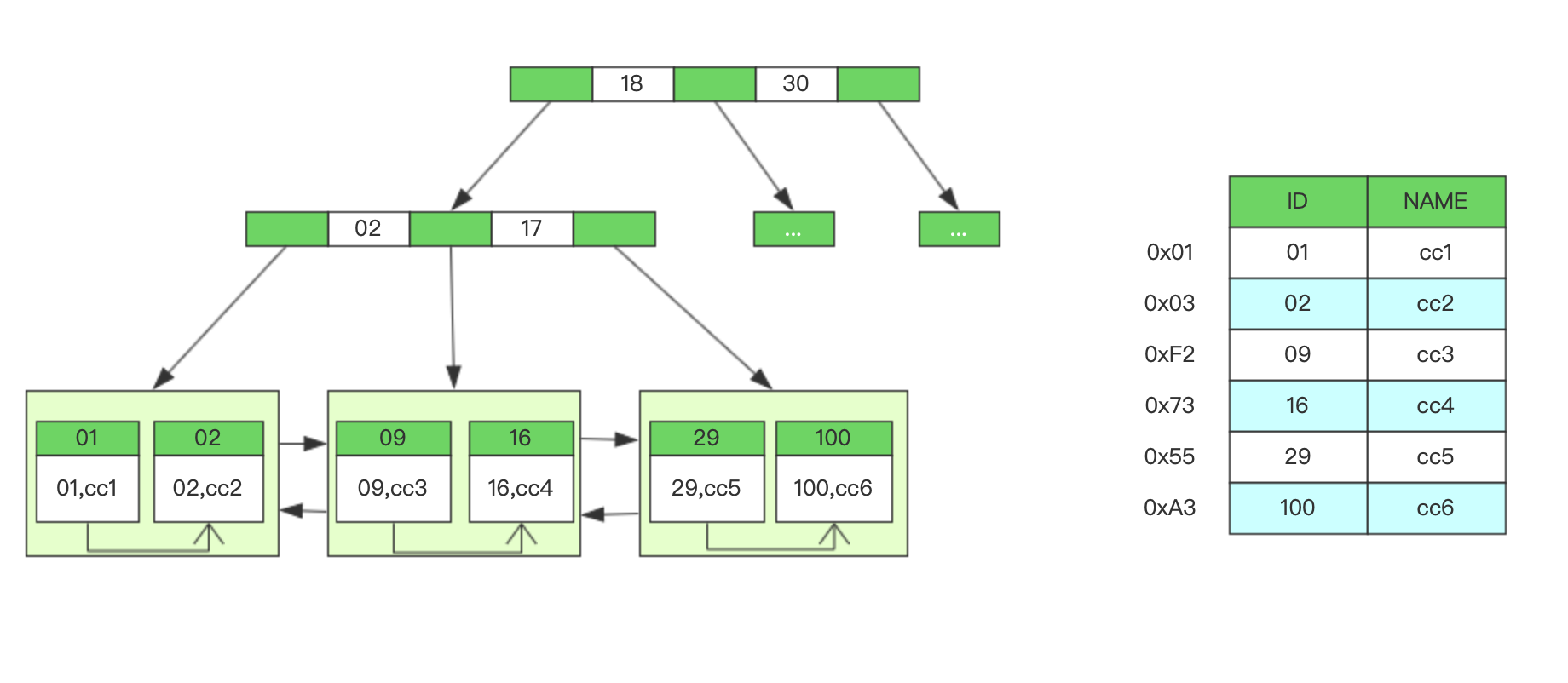
-
特征
B+树在非叶子节点存储关键字和指向下一节点的指针,仅在叶子节点存储数据,叶子节点之间依据关键字从小到大有序排列成一个有序链表;
B+树是B树的一个升级版,相对于B树来说B+树更充分的利用了节点的空间,让查询速度更加稳定,其速度完全接近于二分法查找;
所有的叶子节点都在同一高度上,对于所有内部节点,子指针的数目总是与元素的数目相同。
-
作为索引
- 非叶子节点不保存关键字记录的指针,只进行数据索引,这样使非叶子节点能保存大量的关键字
- 所有的数据或数据地址只有在叶子节点才能获取到,所以每次查询所有的路径相同,查询稳定
- 非叶子节点的关键字都是从小到大有序排列
- 所有的叶子节点形成有序链表,方便于范围查询
-
总结
以上的内容带我们认识了什么是索引、索引有什么用、索引有哪些存储结构,基本上对索引有了一个最基本的认识,通过对几个存储结构的分析,我们可以看出为什么MySQL选择B+树:每一次的演变都是为了提供更快的查询,如何加快查询效率,就是减少IO的操作次数。