[Toc]
什么是Spring Cloud
官网上面有一段话:Spring Cloud为开发人员提供了快速构建分布式系统中的一些常见模式的工具(例如配置管理、服务发现、断路器、智能路由、微代理、控制总线、一次性令牌、全局锁、领导选举、分布式会话、集群状态)。
- Spring Boot是Spring的一套快速配置脚手架,可以基于Spring Boot快速开发一个微服务应用,而Spring Cloud是一个基于Spring Boot实现云应用的开发工具;
- Spring Boot专注于快速、方便的创建单个微服务,Spring Cloud专注于微服务全局的服务治理框架;
- Spring Boot使用了约定大于配置的理念,大部分集成方案都预设好了,不需要过多的配置,或者说能不配置就不配置,而Spring Cloud是基于Spring Boot来实现的,也就是说Spring Boot可以独立于Spring Cloud,而Spring Cloud强依赖于Spring Boot。
什么是微服务
####微服务架构
- 分散:不同的功能模块部署在不同的服务器/容器中,减轻功能模块高并发带来的压力
- 集群:不同服务器/容器中部署相同的功能模块,通过负载均衡服务配置实现功能模块的高可用
- 微服务:微服务架构简单来说就是将web应用拆分成一系列小的服务应用,这些应用可以独立的编译、部署,应用之间通过暴露各自的API实现通信,共同组成一个完整的web应用
####微服务的特点
- 单一职责:每一个微服务模块都对应不同的服务功能,负责单一业务的业务实现
- 微/细:服务拆分的粒度很小,但依据分久必合合久必分原则,微服务之间也是可以进行再拆分或合并的
- 面向服务:每个服务应用对外暴露自己的API,调用者不需要关注具体的业务实现
- 自我治理:
- 服务独立,研发团队独立
- 技术独立:只要提供相应的API即可,实现技术和实现语言不必一致
- 前后端分离
- 配置独立
- 解耦:独立部署,通过RPC或REST方式通信,耦合影响较小
- 服务容错、限流
####微服务的劣势
- 微服务使整个应用分散成多个服务应用,定位问题非常困难(trace解决定位难的问题)
- 稳定性下降,服务数量过多会导致整个应用出现问题的概率变大,其中一个服务挂掉就可能导致整个应用不可用,访问量越大出问题的可能性越大
- 服务数量过多,部署、管理的工作量变大
- 开发的过程中很难实现相互依赖的服务之间同步进行(mock解决此问题)
- 测试难度增大,由原先的单体应用测试变成服务间调用的测试,测试过程更加复杂
- 服务运行过程中可能会经常发生服务宕机,所以对于微服务必须建立完善的服务监控体系,尽可能的第一时间发现故障服务并进行故障通知、转移和恢复(Zookeeper、Eureka、Consul、Etcd等)
####微服务拆分依据
微服务拆分不是一蹴而就的,而是需要在开发过程中不断的去分析和理清每一个服务的边界。对于老工程中尚未分清拆分方向的,可先留于其中,最终可考虑将这些功能作为一个微服务。
- 基于业务逻辑
- 基于可扩展
- 基于可靠性
- 基于性能
####微服务拆分规范
- 粒度:先少后多,先粗后细
- 调用:保持单向调用,尽量禁止循环调用,比如订单—>产品,产品—x>订单
- 接口幂等:应保证接口的幂等性,避免出现脏数据
- 纵向拆分尽量少于三层,也即维持在控制层—>业务服务层—>基础服务层
- 先拆分服务,后拆分数据库
基础元件
####Config
分布式服务,由于服务数量较多,每一个服务都会有1+套配置文件,如果每个项目单独配置一个yml/properties文件,管理起来会很混乱,并且无法实现动态变更配置属性的值,所以我们需要一个分布式配置中心组件,Spring Cloud Config就因此应运而生,它支持配置信息放在配置服务的内存中,也支持放在远程的git/svn仓库中,Config分两个角色,一个Server和一个Client。
-
Server:创建一个简单的Config Server,使用git作为配置中心,我们再git仓库中创建目录config,这个目录名称需要和
spring.cloud.config.server.git.search-paths配置的一致,然后在目录中创建client1-dev.properties-
pom.xml
1
2
3
4<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-config-server</artifactId>
</dependency> -
application.properties
1
2
3
4
5=7701
=http://gitlab.xx.com/spring-cloud/config-center.git
=xxxxx
=xxxxx
=config- spring.cloud.config.server.git.uri:git仓库地址
- spring.cloud.config.server.git.search-paths:git仓库地址下的相对地址,可以配置多个,用,分割
- spring.cloud.config.server.git.username:git仓库登录用户名
- spring.cloud.config.server.git.password:git仓库登录密码
-
启动类
1
2
3
4
5
6
7
8
9
public class SpringCloudConfigApplication {
public static void main(String[] args) {
SpringApplication.run(SpringCloudConfigApplication.class, args);
}
}我们再启动类加上
@EnableConfigServer注解,表明该项目是Config Server项目,启动后访问http://localhost:7701/client1/dev,如果返回如下,则表示我们已经配置正常,可以使用:{
“name”: “client1”,
“profiles”: [
“dev”
],
“label”: null,
“version”: “e3741fe5e48b303c80f34c1b8a44c0ef2999e22b”,
“state”: null,
“propertySources”: [
{
“name”: “http://gitlab.xxx.com/spring-cloud/config-demo.git/config/client1-dev.yml”,
“source”: {
“name”: “cc”
}
}
]
}☆说明:
仓库中的配置文件会被转换成 Web 接口,访问可以参照以下的规则:
- /{application}/{profile}[/{label}]
- /{application}-{profile}.yml
- /{label}/{application}-{profile}.yml
- /{application}-{profile}.properties
- /{label}/{application}-{profile}.properties
上面的 URL 会映射
{application}-{profile}.yml对应的配置文件,其中{label}对应 Git 上不同的分支,默认为 master。以 config-client-dev.yml 为例子,它的 application 是 config-client,profile 是 dev。
-
-
Client
-
pom.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15<!-- web项目 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- config -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-config</artifactId>
</dependency>
<!-- 动态刷新配置信息 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>我们引入了actuator,目的是可以在修改了git仓库中的配置信息之后,可以手动刷新,让项目读取最新的配置信息,而不需要重启我们的应用
-
bootstrap.properties
config的配置必须配置在bootstrap.properties文件中,这样才能被正确的加载,按照springboot的配置文件加载顺序来看,会先加载bootstrap,然后再加载application,并且我们的config的配置要优先于项目中的其他内容
1
2
3
4=dev
=dev
=http://127.0.0.1:7701/
=client1- label:对应git仓库的分支名称,默认是master,我们这里dev表示我们使用的是dev分支,若分支不存在,则报错
- profile:环境,对应文件后缀
- uri:Config Server地址
- name:配置中心的项目文件夹名称,若配置一个不存在的文件名,则会报错
-
application.properties
1
2
3=client1
=8080
=health, info, refresh在application.properties中指定端口和项目名称,因为我们引入的actuator,但是它默认暴露的接口是health和info两个接口,其他的都涉及到安全所以需要手动将接口暴露出来,因为我们要可以动态刷新,所以将refresh接口也暴露出来,以POST方式请求该接口:
curl -X POST http://127.0.0.1:8080/actuator/refresh -
TestController.java
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
("/index")
public class TestController {
("${name}")
private String name;
("/one")
public String one() {
System.out.println(name);
return name;
}
}注解
@RefreshScope是指明该类下的属性注入可以动态刷新
-
-
测试
- 访问http://127.0.0.1:8080/index/one
- 修改client-dev.properties文件中name=one_1
- 刷新:
curl -X POST http://127.0.0.1:8080/actuator/refresh - 访问http://127.0.0.1:8080/index/one
-
Eureka
服务注册发现中心,基于CAP理论的AP实现,一个基于REST的服务,用于服务的发现和定位,以实现云端中间层服务发现和故障转移。Eureka的AP原则保证了注册中心的高可用,它是一个去中心化的架构,也就是集群中的所有节点都无主从之分,每一个节点都是平等的,可以相互注册,每一个节点都需要添加一个或多个serviceUrl指向其他节点,每个节点都可以视为其他节点的副本,这一特点实现了Eureka的高可用。
当有一台Server宕机后,Eureka Client会将请求自动转发到其他的Server节点上,当故障的Server节点恢复之后,Eureka会将其再次加入到服务器集群中。
当一个新的Server启动并加入进群后,会首先从其他的临近节点获取所有的可用服务列表信息完成初始化。
-
Server:创建一个Eureka Server中心只需要在启动类上加上注解
@EnableEurekaServer即可,启动服务之后通过访问http://127.0.0.1:8080/进入eureka控制中心,我们需要在pom.xml中引入一个jar包1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
<version>2.2.6.RELEASE</version>
</dependency>
↓(内嵌)
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-netflix-eureka-server</artifactId>
<version>2.2.2.RELEASE</version>
<scope>compile</scope>
</dependency>
↓(内嵌)
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-netflix-eureka-client</artifactId>
<version>2.2.2.RELEASE</version>
<scope>compile</scope>
</dependency>1
2
3
4
5
6
7
public class EurekaServerApplication {
public static void main(String[] args) {
SpringApplication.run(EurekaServerApplication.class, args);
}
}如果我们仅仅是部署一个Eureka Server,那么我们还需要修改一下eureka.client前缀的配置
1
2
3=false
=false
=http://127.0.0.1:${server.port}/eureka/这些配置信息对应的类是在
spring-cloud-netflix-eureka-client.jar包中的org.springframework.cloud.netflix.eureka.EurekaClientConfigBean类中,看下这个类中上面三个参数的默认值:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24(EurekaClientConfigBean.PREFIX)
public class EurekaClientConfigBean implements EurekaClientConfig, Ordered {
// 默认的eureka客户端配置前缀,就用在上面↑
public static final String PREFIX = "eureka.client";
// Eureka默认的访问地址,如果我们不修改这个配置的话,就可以通过8761端口的这个地址去访问
public static final String DEFAULT_URL = "http://localhost:8761" + DEFAULT_PREFIX
+ "/";
// 如果没设置zone就使用下面这个默认的
public static final String DEFAULT_ZONE = "defaultZone";
// 指定是否将当前服务注册到Eureka Server以被其他服务发现和使用
// 如果不想使当前应用被其他服务发现,则修改此属性为false
private boolean registerWithEureka = true;
// 指定当前服务是否从Eureka Server拉取监听的服务列表
private boolean fetchRegistry = true;
// Eureka Server访问地址,一个Map,可以存储很多值
private Map<String, String> serviceUrl = new HashMap<>();
{
// 将默认的server地址放入服务地址Map中
this.serviceUrl.put(DEFAULT_ZONE, DEFAULT_URL);
}
} -
Client:创建一个Eureka Client很简单,在启动类上加上注解
@EnableEurekaClient即可,如果Eureka Server服务的端口并不是使用的8761,那么则需要修改一下配置信息:1
=http://127.0.0.1:8080/eureka/
仅仅只需要修改折一个配置即可,因为其他的默认都为true,不用再配置了,这就是Spring Boot所说的约定大于配置
1
2
3
4
5
6
7
public class EurekaServerApplication {
public static void main(String[] args) {
SpringApplication.run(EurekaServerApplication.class, args);
}
} -
自我保护模式
- Eureka Server在运行期间会不断的统计心跳失败比例,如果再15分钟内有超过85%的client未正常发送心跳过来(单机模式很容易满足,生产环境如果出现这个情况则一般是网络通信出现了问题),那么Eureka Server就会认为自己和客户端出现了网络故障,就会进入自我保护模式
-
-
自我保护模式的原则是宁可放过不可错杀,意思就是即使服务宕机了,我们在注册中心看到的服务状态依然是UP
- 自我保护模式使的Eureka实现了CAP中的AP,默认是开启的,可以通过参数
eureka.server.enable-self-preservation=false进行关闭,但是在实际生产环境中不建议关闭,因为如果关闭的话,可能就直接导致服务不可用了
- 自我保护模式使的Eureka实现了CAP中的AP,默认是开启的,可以通过参数
-
在正常情况下,如果超过默认的90秒未接收到某client的心跳,则将该client做下线处理,并从服务列表中移除掉;但是在保护模式下,不会将无心跳的client从服务列表中移除
- 自我保护模式下,当前Server节点依然可以接收通信正常的服务的注册和发现,但是不会将新注册的服务同步给集群中的其他Server节点,只有待网络恢复且退出自我保护模式之后,才会将自我保护模式期间新注册的服务同步给其他节点
- Eureka的服务健康检查是通过actuator的/info和/health来实现的
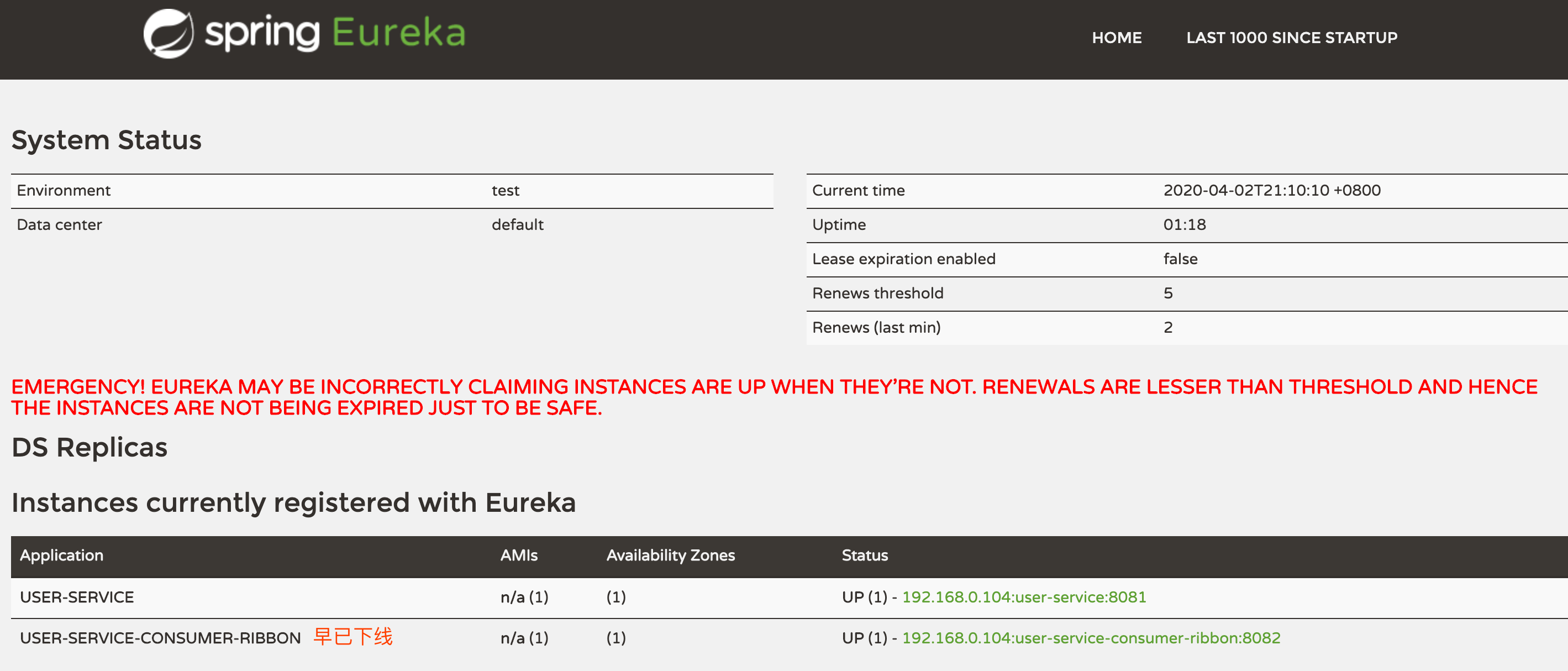
####Consul
Consul用于实现分布式系统的服务发现与配置,其它分布式服务注册与发现的方案,满足CAP的CP,Consul 的方案更“一站式”,内置了服务注册与发现框 架、分布一致性协议实现、健康检查、Key/Value 存储、多数据中心方案,不再需要依赖其它工具(ZooKeeper等),Consul可以与Docker完美融合使用Go语言开发,基于 Mozilla Public License 2.0 的协议开源。
-
Consul工作原理
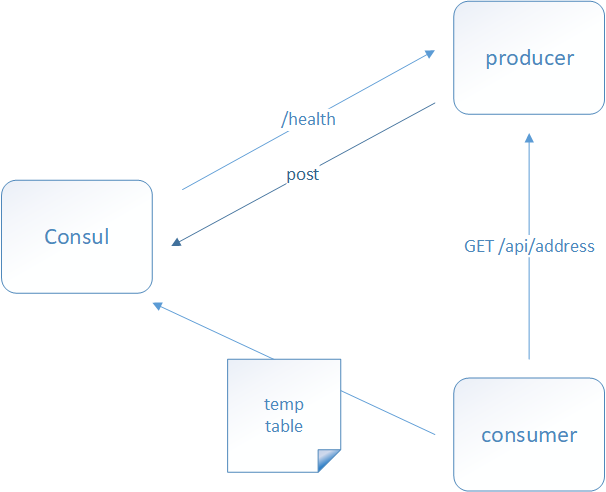
- Producer启动的时候,会向Consul发送自己的服务信息,比如IP、port等
- Consul每隔10秒(默认)会向Producer发送一个心跳监控请求,检测Producer是否健康
- Consumer每隔10秒(默认)会向Consul拉取一次服务列表缓存在本地,Consumer的请求都基于本地的服务缓存列表进行请求
-
安装Consul服务
-
Docker运行(单机版)
1
2
3
4
5
6
7
8
9
10
11
12
131. 查询consul可用镜像
docker search consul
2. 拉取consul镜像
docker pull consul:latest
3. 启动镜像
docker run \
--name consul \
-p 8599:8500 \
-v /data/consul/conf/:/consul/conf/ \
-v /data/consul/data/:/consul/data/ \
-d consul -
正常安装
下载地址:https://www.consul.io/downloads.html
帮助文档:https://learn.hashicorp.com/consul/getting-started/install
-
访问consul:http://127.0.0.1:8599
-
-
Consul与客户端集成
-
pom.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15<!-- web包,必须引入,否则服务无法注册到注册中心 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- consul discovery -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-consul-discovery</artifactId>
</dependency>
<!-- 心跳 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency> -
application.properties
1
2
3
4
5=7702
=consul-demo
=127.0.0.1
=8500
#spring.cloud.consul.discovery.health-check-path=/health- spring.cloud.consul.host:consul服务IP
- spring.cloud.consul.port:consul服务端口
- spring.cloud.consul.discovery.health-check-path:consul心跳地址,默认为actuator/health,我们可以自定义
-
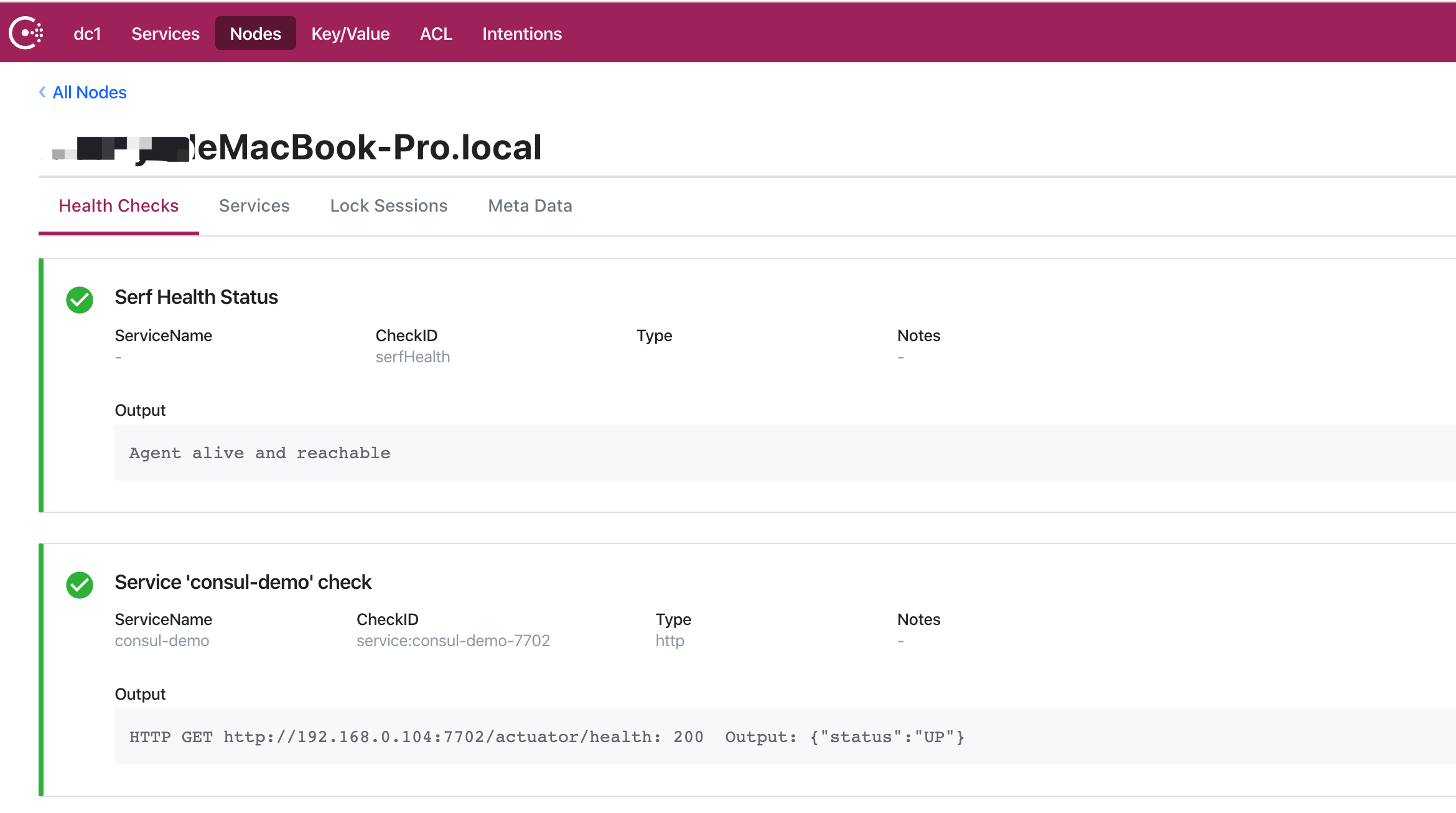
启动类
1
2
3
4
5
6
7
8
9
10// 利用注解@EnableDiscoveryClient开启服务自动注册和发现
public class SpringCloudConsulApplication {
public static void main(String[] args) {
SpringApplication.run(SpringCloudConsulApplication.class, args);
}
}
-
-
运行机制
- Consul的一致性算法采用了Raft,比Zookeeper的Paxos算法简单很多
- 强一致性给Consul带来了可用性的下降
- 当一个服务注册到leader节点时,因为Raft算法要求所有节点数投票同意过半才能将服务真正的注册进来,所以新服务注册的时间被拉长了
- 当leader节点挂掉之后,需要根据Raft算法选举出新的leader节点,选举的过程中,Consul服务不可用
####Ribbon
负载均衡(Load Balance)是用于解决一个服务节点无法处理所有请求的算法,Ribbon是一款基于TCP和HTTP的客户端负载均衡工具,基于Netflix Ribbon,由Spring Cloud进行了再封装,将我们的REST模板的请求均转换为客户端负载均衡的服务调用,Ribbon仅仅只是一个工具,包含在每一个Spring Cloud应用中,无需单独的部署其他服务。
由于Ribbon属于是客户端负载均衡,所以需要在客户端维护一份服务端列表信息,而这些列表信息来自于服务注册中心,如Eureka、Consul等,客户端的服务端列表信息也需要不断的去更新,保证服务列表中服务的可用性,这个过程并不是在客户端去检测各个服务端的心跳,而是通过与服务注册中心进行数据交换来维护服务端的健康。
Spring Cloud默认会自动加载和配置Ribbon的一切,我们只需要去解读一下org.springframework.cloud.netflix.ribbon.eureka.RibbonEurekaAutoConfiguration和org.springframework.cloud.consul.discovery.RibbonConsulAutoConfiguration就可以知道一切了,这里不做源码解释
-
如何在Spring Cloud中使用Ribbon
- 服务端启动多个实例,并注册到同一个服务注册中心,或者同一个集群
- 客户端的RestTemplate实例创建的时候通过注解
@LoadBalanced修饰
-
Ribbon带来的好处
- 当集群中某一个服务宕掉后,整个服务集群依然可以正常提供服务
- 可以选择合适的负载算法保证服务的良性使用,避免在流量激增的时候拖垮CPU
-
负载均衡算法
-
权重
为每台机器设置在集群中的比重,请求过来后按照比重分配进行轮询
-
随机
对集群中的机器随机访问,通过随机数定位要访问的机器
-
哈希
请求按照一定规则映射到要访问的机器上
-
轮询
轮询是指将请求轮流分配给每台服务器,当服务器群中各服务器的处理能力相同时,且每笔业务处理量差异不大时,最适合使用这种算法
-
-
Ribbon工作原理
-
获取被
@LoadBalanced修饰的RestTemplate我们知道SpringBoot中的自配装配都是通过MATE-INF/spring.factories文件中
org.springframework.boot.autoconfigure.EnableAutoConfiguration指定的类来实现的,在注解@LoadBalanced所在的包中我们找到了org.springframework.cloud.client.loadbalancer.LoadBalancerAutoConfiguration,其实整个EnableAutoConfiguration的列表中只有这一个和LoadBalance有关,所以很容易找,我们看下LoadBalanceAutoConfiguration的代码是怎么写的1
2
3
(required = false)
private List<RestTemplate> restTemplates = Collections.emptyList();我们知道
@Autowired可以将对象赋值给一个对象,也可以赋值给一个对象的集合,这里我们不做解释,可以去了解一下@Autowired和@Qualifier。 -
为RestTemplate添加一个拦截器,也就是
org.springframework.cloud.client.loadbalancer.LoadBalancerInterceptor,拦截每一次的RestTemplate请求我们看下LoadBalancerInterceptor的创建过程:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
public SmartInitializingSingleton loadBalancedRestTemplateInitializerDeprecated(
final ObjectProvider<List<RestTemplateCustomizer>> restTemplateCustomizers) {
return () -> restTemplateCustomizers.ifAvailable(customizers -> {
for (RestTemplate restTemplate : LoadBalancerAutoConfiguration.this.restTemplates) {
for (RestTemplateCustomizer customizer : customizers) {
// 触发LoadBalancerInterceptorConfig.restTemplateCustomizer的执行
customizer.customize(restTemplate);
}
}
});
}
("org.springframework.retry.support.RetryTemplate")
static class LoadBalancerInterceptorConfig {
// 创建拦截器
public LoadBalancerInterceptor ribbonInterceptor(
LoadBalancerClient loadBalancerClient,
LoadBalancerRequestFactory requestFactory) {
return new LoadBalancerInterceptor(loadBalancerClient, requestFactory);
}
// 为RestTemplate实例添加拦截器
public RestTemplateCustomizer restTemplateCustomizer(
final LoadBalancerInterceptor loadBalancerInterceptor) {
return restTemplate -> {
List<ClientHttpRequestInterceptor> list = new ArrayList<>(
restTemplate.getInterceptors());
list.add(loadBalancerInterceptor);
// 拦截器设置点
restTemplate.setInterceptors(list);
};
}
} -
在拦截器中获取服务所有的列表,根据负载规则选择一台机器提供服务
通过上面的分析,我们可以看到只要为RestTemplate添加了拦截器之后,根据拦截器的工作性质,往后通过RestTemplate实例的每一次请求都会先走到这个拦截器的intercept()方法中,在intercept()方法中调用了
LoadBalancerClient.execute()进行了Server选举。1
2
3
4
5
6
7
8
9
10
11
12
13
public <T> T execute(String serviceId, LoadBalancerRequest<T> request) throws IOException {
// 获取服务列表,检测服务是否存活,每一次请求均需要检测一次,所有的路由均实现于ILoadBalancer
ILoadBalancer loadBalancer = getLoadBalancer(serviceId);
// 根据配置的路由规则选择最终要提供的服务的地址,所有的规则都实现于IRule
Server server = getServer(loadBalancer);
if (server == null) {
throw new IllegalStateException("No instances available for " + serviceId);
}
RibbonServer ribbonServer = new RibbonServer(serviceId, server, isSecure(server, serviceId), serverIntrospector(serviceId).getMetadata(server));
return execute(serviceId, ribbonServer, request);
} -
发送请求获取结果,然后将结果返回
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
public <T> T execute(String serviceId, ServiceInstance serviceInstance, LoadBalancerRequest<T> request) throws IOException {
Server server = null;
if(serviceInstance instanceof RibbonServer) {
server = ((RibbonServer)serviceInstance).getServer();
}
if (server == null) {
throw new IllegalStateException("No instances available for " + serviceId);
}
RibbonLoadBalancerContext context = this.clientFactory
.getLoadBalancerContext(serviceId);
RibbonStatsRecorder statsRecorder = new RibbonStatsRecorder(context, server);
try {
// 最终请求语句
T returnVal = request.apply(serviceInstance);
statsRecorder.recordStats(returnVal);
return returnVal;
}
catch (IOException ex) {
statsRecorder.recordStats(ex);
throw ex;
}
catch (Exception ex) {
statsRecorder.recordStats(ex);
ReflectionUtils.rethrowRuntimeException(ex);
}
return null;
}借他人的一张图来说明一下请求流程:
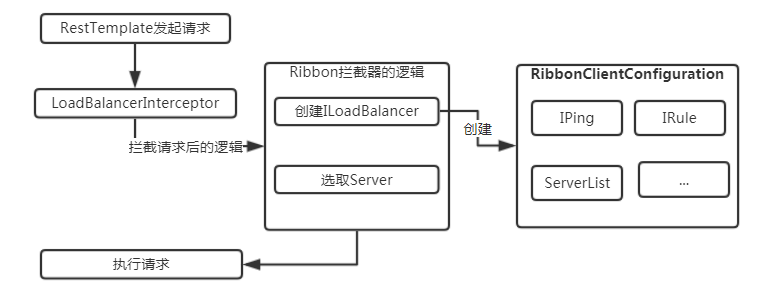
-
-
配置负载策略
Ribbon默认的负载策略为ZoneAwareLoadBalancer,我们可以通过配置修改策略方案
-
使用Ribbon中已存在的负载策略
1
=com.netflix.loadbalancer.RandomRule
所有的策略都实现于IRule接口
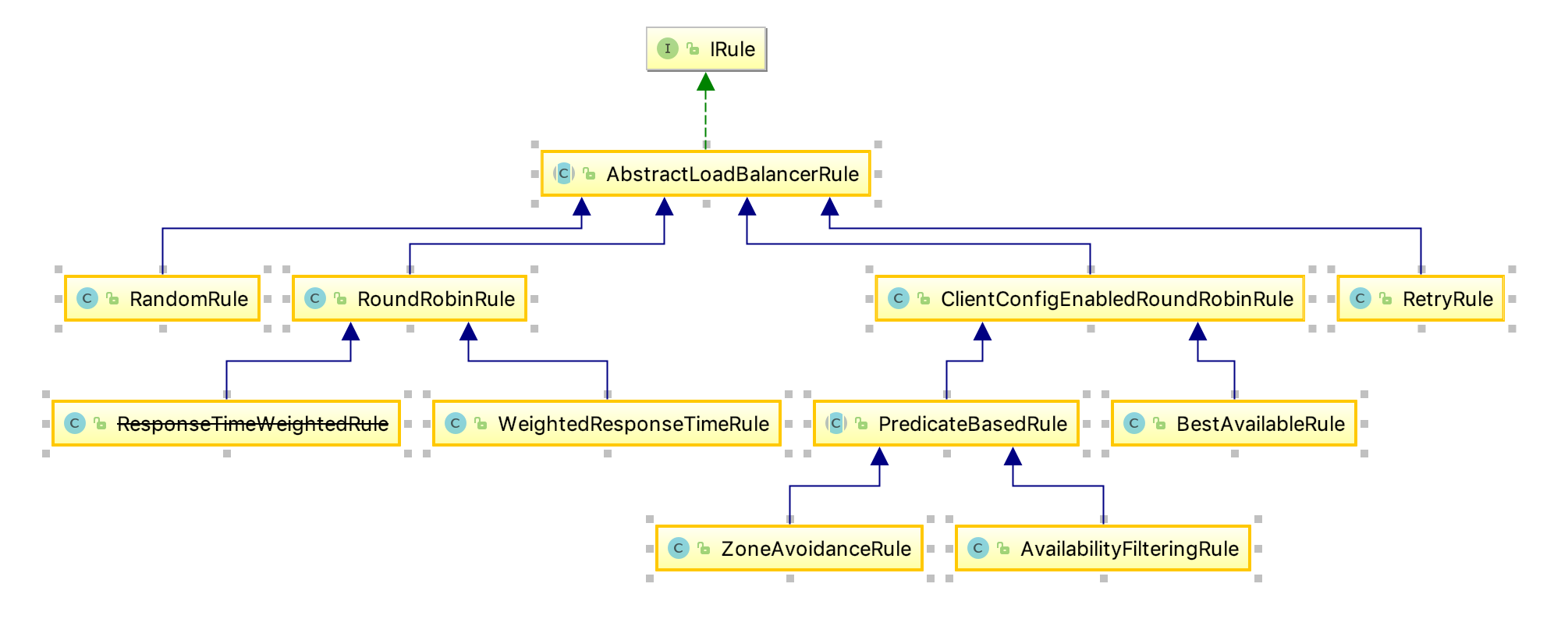
这里单独说一下WeightedResponseTimeRule这个策略,我们在使用Nginx的时候,可以手动预先设置好每一台服务器的权重,但是在Ribbon中,权重是依据服务器响应时间动态设置的,在应用运行期间,这个权重有可能会改变,在WeightedResponseTimeRule类中有一个内部类DynamicServerWeightTask,它是一个定时器,调度时间默认为30秒一次,如果想要修改这个时间,则可以使用自定义负载规则。
-
使用自定义负载策略
-
创建自定义配置器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
public class MyRule {
public IRule ribbonRule() {
// 使用权重规则
WeightedResponseTimeRule rule = new WeightedResponseTimeRule();
IClientConfig config = new DefaultClientConfigImpl();
config.loadDefaultValues();
// 修改权重定时器执行时间
config.set(WeightedResponseTimeRule.WEIGHT_TASK_TIMER_INTERVAL_CONFIG_KEY, 5 * 1000);
// 调用方法修改配置
rule.initWithNiwsConfig(config);
return rule;
}
} -
声明要使用该规则的服务
在启动类上加入
@RibbonClient(name = "user-service", configuration = MyRule.class),name属性指定服务名称,configuration指定要使用的规则
-
-
####Hystrix
Spring Cloud Hystrix是从Netflix Hystrix延伸出的一个轻量级的组件,主要功能是服务容错和线程隔离。
在微服务架构中,服务之间通过远程调用的方式进行通信,会出现一个请求走过多个服务的情况,在请求链路中,一旦某个服务出现故障,那么所有依赖这个服务的其他服务均会发生故障,严重的情况下会导致整个系统全部瘫痪,这与我们做微服务的初衷是相悖的。Hystrix的断路器模式帮我们提升了服务的故障容错能力,当某个服务或某个接口出现故障时,通过断路器的监控,给调用方返回一个指定的错误响应,避免调用方因为长期等待一直占用线程而造成的故障蔓延。
Hystrix具备服务降级、服务熔断、线程隔离、请求缓存、请求合并和服务监控等功能,我们常用的大多就是降级和熔断了。
-
服务熔断降级
服务熔断是指在下游服务变得不可用或响应时间过长而导致调用方放弃继续调用转而直接返回的一种处理方式,目的是为了保证上游服务的可用性和稳定性。然后我们创建一个具有熔断器的项目,下游服务的代码不做解释,我们看下上游服务如何开启熔断。
-
pom.xml
我们要使用Hystrix的第一步当然是要引入jar包,我们在pom.xml文件中引入依赖jar:
1
2
3
4
5
6
7
8
9
10
11
12
13
14<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- euraka -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
<!-- Hystrix -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
</dependency>为什么要引入eureka?因为服务端是注册到eureka里面的啊,所以要引入eureka去做服务发现。那么可以不用eureka么?当然可以。
-
API
1
2
3
4
5
6
7
8
9
10(fallbackMethod = "faultMethod")
("/cuser")
public String getUser() {
String obj = restTemplate.getForObject("http://cuser-service/user/1", String.class);
return obj;
}
public String faultMethod() {
return "服务熔断";
}API的定义和我们平时写的不太一样,多了一个注解
@HystrixCommand,这个注解的作用就是在我们API内发生异常的时候进行熔断,参数fallbackMethod指定的就是在发生异常的时候跳转的熔断方法,这个方法参数和返回类型需要和被熔断的方法如出一辙,否则就会报错。- 注解
@HystrixCommand参数解析- fallbackMethod:指定服务降级处理方法;
- ignoreExceptions:忽略某些异常,不发生服务降级;
- commandKey:命令名称,用于区分不同的命令;
- groupKey:分组名称,Hystrix会根据不同的分组来统计命令的告警及仪表盘信息;
- threadPoolKey:线程池名称,用于划分线程池。
- 注解
-
启动类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
public class SpringCloudCuserConsumerHystrixApplication {
public static void main(String[] args) {
SpringApplication.run(SpringCloudCuserConsumerHystrixApplication.class, args);
}
public RestTemplate restTemplate() {
return new RestTemplate();
}
}注解
@EnableHystrix的作用是为应用开启Hystrix的能力,等于一个开关。老版本中使用的是注解@EnableCircuitBreaker,新版本中可以看到EnableHystrix中已经集成在一起了,所以我们使用这一个注解就行了。运行过程就不用说了,也就是eureka、server、client都启动了,然后访问
http://127.0.0.1:8090/cuser,接着把server停掉,然后再访问,会发现接口发生了熔断。 -
高级参数配置
注解
@HystrixCommand中可以通过参数commandProperties、threadPoolProperties设置熔断降级相关的参数,参数名称在类com.netflix.hystrix.contrib.javanica.conf.HystrixPropertiesManager中有指定,并且类中也说明了这两个属性所适用的参数名称,太多了,写两个比较常用的吧- threadPoolProperties
- coreSize:线程池核心线程数
- keepAliveTimeMinutes:线程最大存活时间,单位为分钟
- maxQueueSize:最大等待线程队列容量
- queueSizeRejectionThreshold:等待队列拒绝添加的阈值
- commandProperties
- execution.isolation.thread.timeoutInMilliseconds:设置调用者等待命令执行的超时限制,超过此时间,HystrixCommand被标记为TIMEOUT,并执行回退逻辑。
- threadPoolProperties
-
-
服务限流
服务接口限流我们可以通过设置注解
@HystrixCommand的threadPoolProperties的参数来实现,限制请求的线程池数量来达到限流的作用1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23static int index = 0;
(fallbackMethod = "faultMethod", threadPoolProperties = {
(name = "coreSize", value = "1"),
(name = "queueSizeRejectionThreshold", value = "2"),
(name = "maxQueueSize", value = "1") }, commandProperties = {
(name = "execution.isolation.thread.timeoutInMilliseconds", value = "2000") })
("/cuser")
public String getUser() {
try {
index++;
if (index % 3 == 0) {
Thread.sleep(3000);
}
} catch (InterruptedException e) {
}
String obj = restTemplate.getForObject("http://cuser-service/user/1", String.class);
return obj;
}
public String faultMethod() {
return "服务熔断";
}我们用index来模拟一个请求挂起的操作,我们线程池核心数设置为1,最大等待队列长度为1,我们用JMeter来模拟45个并发,会发现最终只有3个请求顺利通过,其他的全部都被熔断了。
然后我们修改一下线程池大小
1
2
3
4
5
6> (fallbackMethod = "faultMethod", threadPoolProperties = {
> (name = "coreSize", value = "10"),
> (name = "queueSizeRejectionThreshold", value = "10"),
> (name = "maxQueueSize", value = "100") }, commandProperties = {
> (name = "execution.isolation.thread.timeoutInMilliseconds", value = "2000") })
>把核心数和队列数都增大,然后还是45个并发,会发现全部请求都正常了,把并发改为200后,会发现有那么一两个请求会被熔断
再改一次
1
2
3
4
5
6> (fallbackMethod = "faultMethod", threadPoolProperties = {
> (name = "coreSize", value = "2"),
> (name = "queueSizeRejectionThreshold", value = "2"),
> (name = "maxQueueSize", value = "10") }, commandProperties = {
> (name = "execution.isolation.thread.timeoutInMilliseconds", value = "2000") })
>150个并发,大概平均每次会有32个请求正常访问,其他的全部被熔断,我们的请求熔断过期时间是2秒,一开始会有2个请求进入核心线程去处理,后续会有10个请求进入等待队列,依次去请求
问题:如果我们想把接口限制并发20,怎么办?
1
2
3
4
5
6> (fallbackMethod = "faultMethod", threadPoolProperties = {
> (name = "coreSize", value = "10"),
> (name = "queueSizeRejectionThreshold", value = "2"),
> (name = "maxQueueSize", value = "10") }, commandProperties = {
> (name = "execution.isolation.thread.timeoutInMilliseconds", value = "150000") })
>我们只能大概的控制一下,并不能如此严谨的设置
####Feign
Spring Cloud Feign是从Netflix Feign扩展出来的一套通过声明式服务调用客户端的组件,使用Feign可用帮助我们更简单的构建一个Web服务,我们只需要通过注解来编写接口,就可以完成对服务接口的绑定。Feign对Hystrix有依赖关系,它只是一个简单的REST框架,最终还是需要通过Ribbon去做负载均衡,通过上面的内容可以看出Feign+Eureka+Ribbon是一家人,Feign通过整合Eureka和Ribbon来实现支持负载均衡的客户端服务。
使用Feign,我们需要将下游服务的接口定义引入到当前应用中,毕竟Java是一个面向对象的语言,即便是RPC调用,我们也需要使用相同的参数类型,并且尽量保证我们参与传递的参数都能够被序列化,所以既然我们要引入下游服务的接口定义,那么我们尽量在下游接口定义中定义FeignClient,这样做的好处是,服务可以被多个客户端使用,不需要每个客户端都定义一次 Feign 接口。
客户端需要在启动类上使用注解@EnableFeignClients开启Feign,Feign最终仍然是使用HTTP方式去发起请求。
上游服务A,下游服务B
B:interface(feign client)—>controller
A:dependency#A—>enable discovery client && enable feign clients
-
客户端调用
- 定义要调用的目标API接口
1
2
3
4
5(name = "cuser-service")
public interface CUserService {
("/user/{id}")
String getUser(@PathVariable(name = "id") Integer id);
}这里只需要定义接口即可,接口的参数和请求路径都需要和对应的API一致,接口由注解
@FeignClient标注。- 调用
1
2
3
4
5
6
7
private UserService userService;
("/cuser/{id}")
public String getUser(@PathVariable(name = "id") Integer id) {
return userService.getUser(id);
}
Feign支持多种注解方式:Feign、JAX-RS、SpringMVC。