MySQL存储引擎
MySQL支持多种存储引擎,我们可以通过show engines命令查看当前数据库所支持的存储引擎列表,那么不同存储引擎下的索引实现方式是否会有所不同?那是当然的,但只不过都大同小异而已,我们目前常用的存储引擎大多是InnoDB,主要是因为InnoDB支持事务、行锁、外键等功能,第二常用的就是MyIsam,但是在MySQL5.5版本之后,InnoDB就变成了默认的存储引擎,也可以看出InnoDB的强大和普适性。我们主要记录InnoDB和MyIsam下的索引实现。
MyIsam下的索引
MyIsam使用B+树作为索引结构,叶子节点存储的是目标数据的内存地址,大致结构图如下:
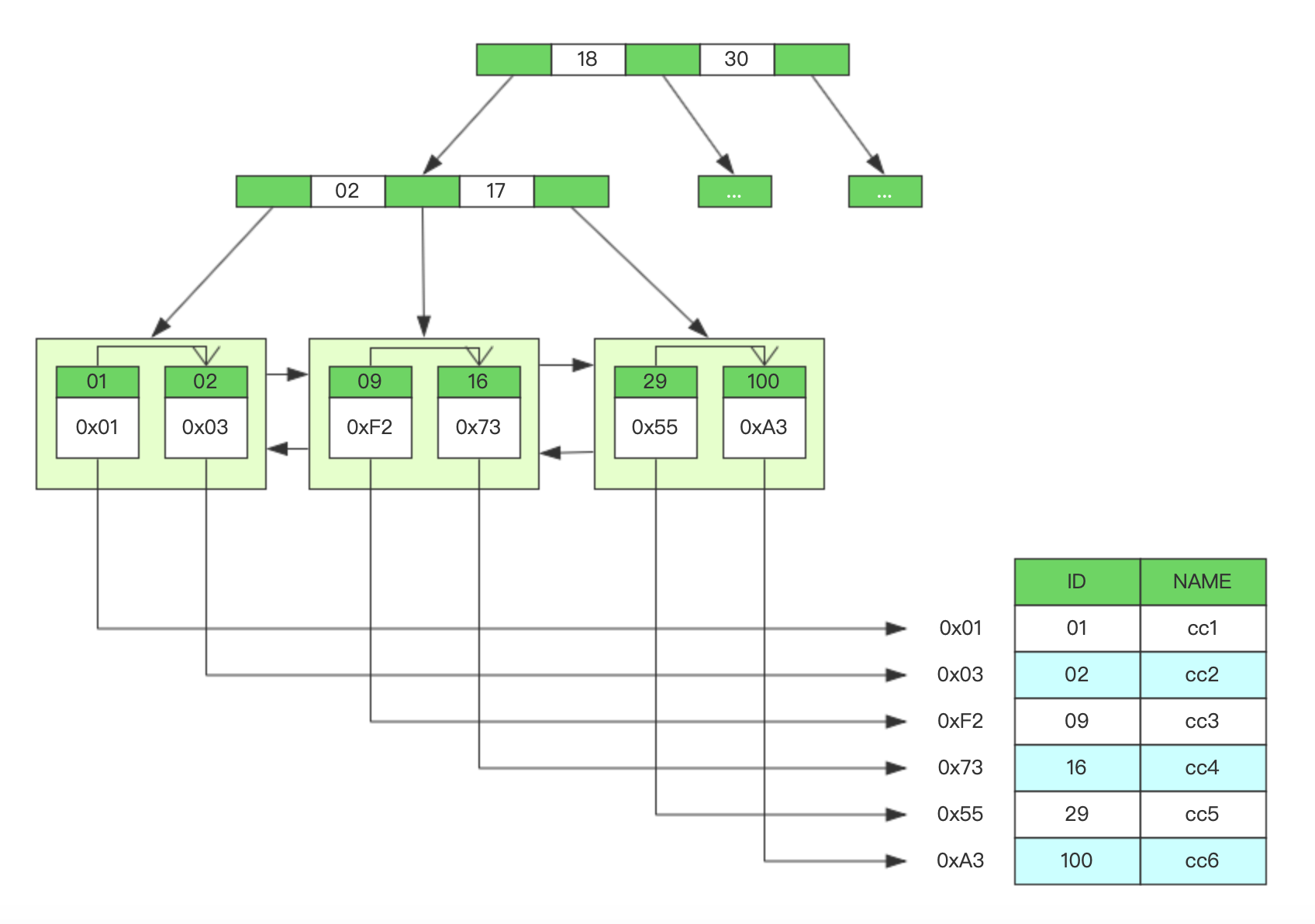
我们发现,每一个叶子节点内存储的都是指向具体数据的内存地址,可以通过地址直接找到数据。那么我们是不是可以推算出MyIsam的索引在磁盘上是怎么存储的?
第一:索引存储的是具体数据的地址,和数据没有关系,只要通过地址就可以找到具体数据了
第二:索引可以单独维护,数据也可以单独维护,就比如是两个微服务项目
由这两点,我们可以推断出MyIsam的索引和数据应该是分开存储的,即索引存储一个文件,数据存储一个文件,当然还应该有表结构定义要单独一个文件,那么一张表是可以创建非常多的索引,是所有的索引都放在一个文件里,还是每个索引都创建一个文件,文件怎么命名?我们去MySQL的data目录下看看
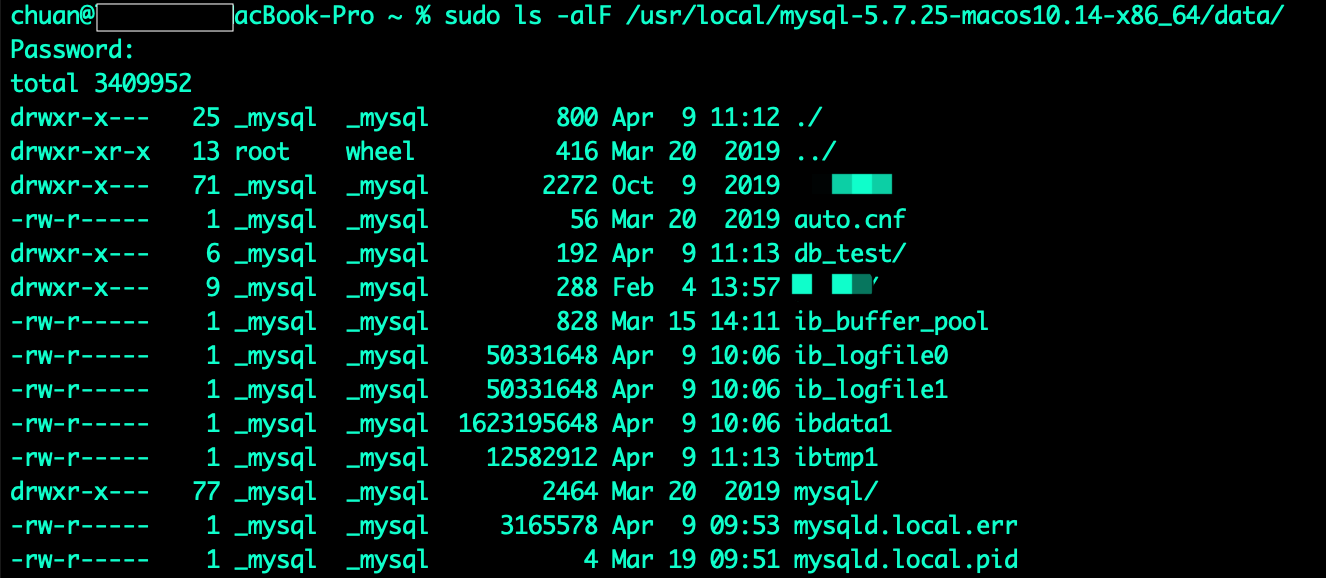
这个目录下有很多的文件夹,每一个文件夹都对应了我们一个用户库,这说明每个库其实都是相互隔离的,隔离的方式就是以目录的形式,我们进到db_test目录下
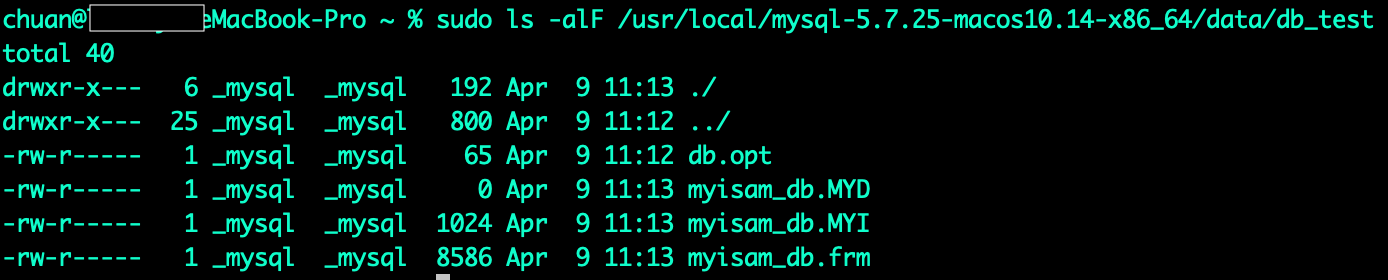
我们事先在db_test库中创建了一张MyIsam引擎的表myisam_db(id, name),并且创建了name字段的索引和id的主键索引,看到这一张表对应了三个文件,且文件是以表的名字命名的
- *.frm:记录描述表结构文件,字段长度等
- *.MYI:索引信息文件,记录所有的索引,My Index
- *.MYD:数据信息文件,存储数据信息, My Data
小结
MyIsam的索引是B+树的数据结构,叶子节点中存储的是数据的地址,实现了索引和数据分离,查询的过程中通过值找到数据地址,然后再根据数据地址将地址内存储的数据捞出返回。
其实我们可以单独的根据文件的存储方式反推出索引的存储策略了,自己反推试试
InnoDB下的索引
InnoDB和MyIsam一样都是采用B+树作为索引的数据结构,不同的在于InnoDB的叶子节点存储的是具体数据,而不是内存地址
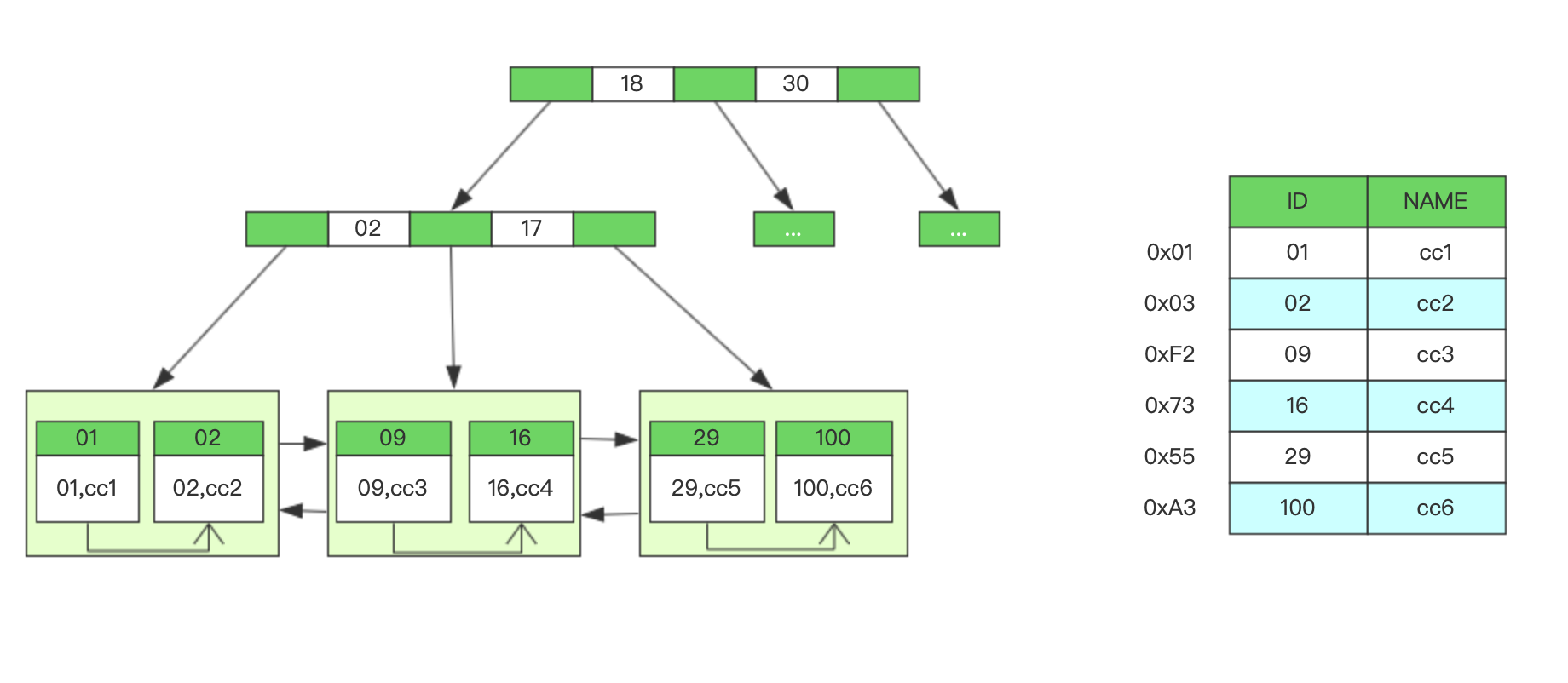
我们都知道MySQL的每张表都必须创建一个主键索引,如果建表时未指定主键,那么MySQL引擎会选择一个非空唯一索引来当主键,若非空唯一索引也没有,那就会自动给添加一个自增的列来作为虚主键,InnoDB和MyIsam在存储上最大的一个区别就是索引和数据在同一个文件中,我们看一下InnoDB的表在磁盘上是怎么存储的。我们先在db_test中创建一张使用InnoDB存储引擎的表innodb_db,然后到/data/db_test目录下查看文件
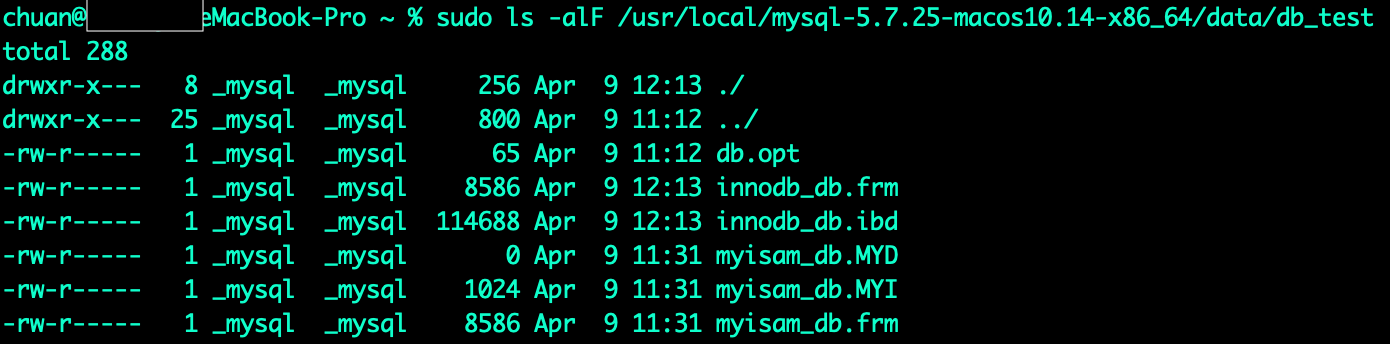
磁盘上针对innodb_test表仅生成了两个文件,*.frm是表结构和字段描述等基础信息文件,重点来说一下*.ibd文件。
- 表空间(Tablespace)
ibd是单表表空间文件,每个表使用一个表空间文件,存放用户数据库表数据、索引,InnoDB的每个数据文件都归属于一个表空间,不同的表空间都有唯一的标识space id来标记,系统表空间文件为ibdata1, ibdata2…,公用同一个表空间,用户创建的表产生的ibd文件都使用唯一的space id,只包含一个文件。
- 页(Page)
表空间文件,其中最基本的单位是页(Page),每一个Page的大小默认为16k,所以ibd的大小必定是16k的整数倍,当然也可以通过innodb_page_size选项将页大小减少到8KB或4KB,或增加到32KB或64KB,但是只能在实例初始化之前设置,不支持动态设置。每个页由header、body、trailer等组成,header标识了类型和checksum信息,可以根据header的类型将body解析成对应的类型,body记录详细的内容,trailer则通过记录checksum等信息来确认该页是否已经写入完成。
- 区(Extent)
Extent用于管理Page,每64个Page组成一个Extent,大小默认为1M,一个Extent内的所有页都是连续的,当表空间页容量不足要分配新页的时候,不会一页一页的分配,会一次性分配一个Extent,也就是连续的64个Page
- 段(Segment)
Segment用于管理Extent,一个表至少会有两个Segment,一个用于管理叶子节点的Extent,一个用于管理非叶子节点的Extent,每增加一个索引就会多出两个Segment,一张表的Segment数量=索引数量*2
Memory下的索引
memory存储引擎是MySQL中的一类特殊的存储引擎。其使用存储在内存中的内容来创建表,而且所有数据也放在内存中,很少用到,至今我没用到过,不过在information_schema库中有很多使用Memory引擎的表。
Memory存储引擎默认使用哈希(HASH)索引,其速度比使用B型树(BTREE)索引快。如果我们需要使用B型树索引,可以在创建索引时选择使用。
Hash索引基于哈希表实现,只有匹配所有列的查询才有效。对于每一行数据,存储引擎都会对所有索引列计算一个哈希码,哈希码是一个较小的值,不同键值的行计算出的哈希码也不一样。哈希索引将所有的哈希码存储在索引中,同时保存指向每个数据行的指针。如果多个列的哈希值相同,索引会以链表的方式存放多个记录指针到同一个哈希条目中去。