聚簇索引
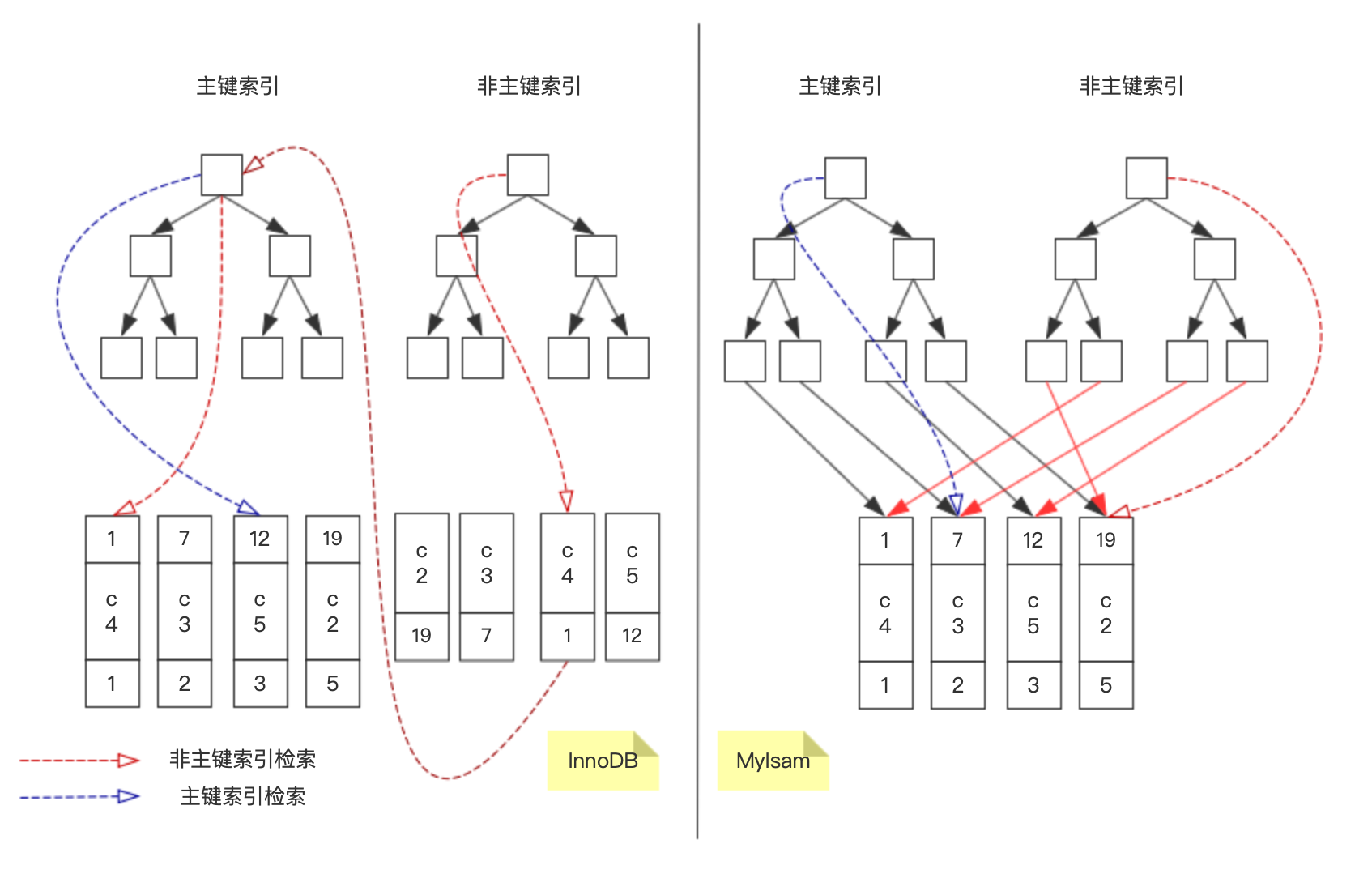
聚簇索引是指叶子节点存储的是一整行记录,比如InnoDB的主键索引,主键和表数据存储在一起。聚簇索引并不是一种单独的索引类型,而是一种数据存储方式,因为一行数据不能同时存储在两个地方,所以一张表中只能有一个聚簇索引,因为一张表的数据存储顺序只能是一种,故只有InnoDB主键索引是聚簇索引。
聚簇索引的存放顺序和数据的物理存储顺序是一致的,即只要是索引是挨着的,那么对应的数据在磁盘上的存储位置一定也是挨着的。
这里有一个问题:如果我们不用自增的字段作为主键,而使用字符串的话,会有什么不妥的地方?我们来分析看下:
- 自增主键:按照主键的值按顺序递增,也就是会一直往后添加数据,只需要分配新页就可以了,那么已经存储了数据的页就永远不会再分裂,物理地址则不需要变动
- 字符串:需要根据字符串的ASSIC码值进行计算所要存储的位置,这个过程中会引起已存储数据的物理地址发生变动,并且需要不断的进行页的分裂,带来的性能开销非常大
优势
- 可以一次性将相邻的数据加载到内存中,减少了磁盘IO次数
- 由于聚簇索引是将索引和数据存储在一起,那么我们找到索引位置的时候实际上就是找到了具体的数据,否则还要进行一次磁盘IO去将最终数据捞出来
劣势
- 插入速度严重依赖于插入顺序:如果使用的是非自增主键,则可能需要进行页的分裂,非常影响性能
- 主键更新代价大:更新一次主键,可能导致被更新的行发生移动,引起页的分裂,非常影响性能
- 二级索引查询需要再次根据主键索引回表查询整行数据,因为InnoDB的二级索引的叶子节点存储的是主键的值
非聚簇索引
非聚簇索引的叶子节点存储的是主键值或行数据存储的物理位置,MyIsam甭管是主键还是非主键索引都是非聚簇索引索引,InnoDB的非主键索引用的也是非聚簇索引,但是这两种存储引擎的非主键索引的叶子节点存储的内容是不同的。
- InnoDB非聚簇索引:叶子节点存储的是主键关键字,当聚簇索引发生页分裂或移动时(主键关键字未变),非聚簇索引不需要改变
- MyIsam非聚簇索引:所有索引的叶子节点存储的都是行数据的物理磁盘存储地址,只要行数据发生位置移动时,会引起所有的索引发生改变
总结
-
聚簇索引叶子节点存储的是行数据,非聚簇索引的叶子节点存储的是主键关键字或数据物理存储地址
-
InnoDB的主键索引是聚簇索引,InnoDB的二级索引和MyIsam的所有索引都是非聚簇索引
-
InnoDB非聚簇索引叶子节点存储的是主键关键字,MyIsam非聚簇索引叶子节点存储的是数据物理存储地址
-
聚簇索引尽量使用自增列,可以减少页分裂和行存储位置移动,提升性能