前言
Consul是一个基于CP的轻量级分布式高可用的系统,提供服务发现、健康检查、K-V存储、多数据中心等功能,不需要再依赖其他组件(Zk、Eureka、Etcd等)。
- 服务发现:Consul可以提供一个服务,比如api或者MySQL之类的,其他客户端可以使用Consul发现一个指定的服务提供者,并通过DNS和HTTP应用程序可以很容易的找到所依赖的服务。
- 健康检查:Consul客户端提供相应的健康检查接口,Consul服务端通过调用健康检查接口检测客户端是否正常
- K-V存储:客户端可以使用Consul层级的Key/Value存储,比如动态配置,功能标记,协调,领袖选举等等
- 多数据中心:Consul支持开箱即用的多数据中心
架构介绍
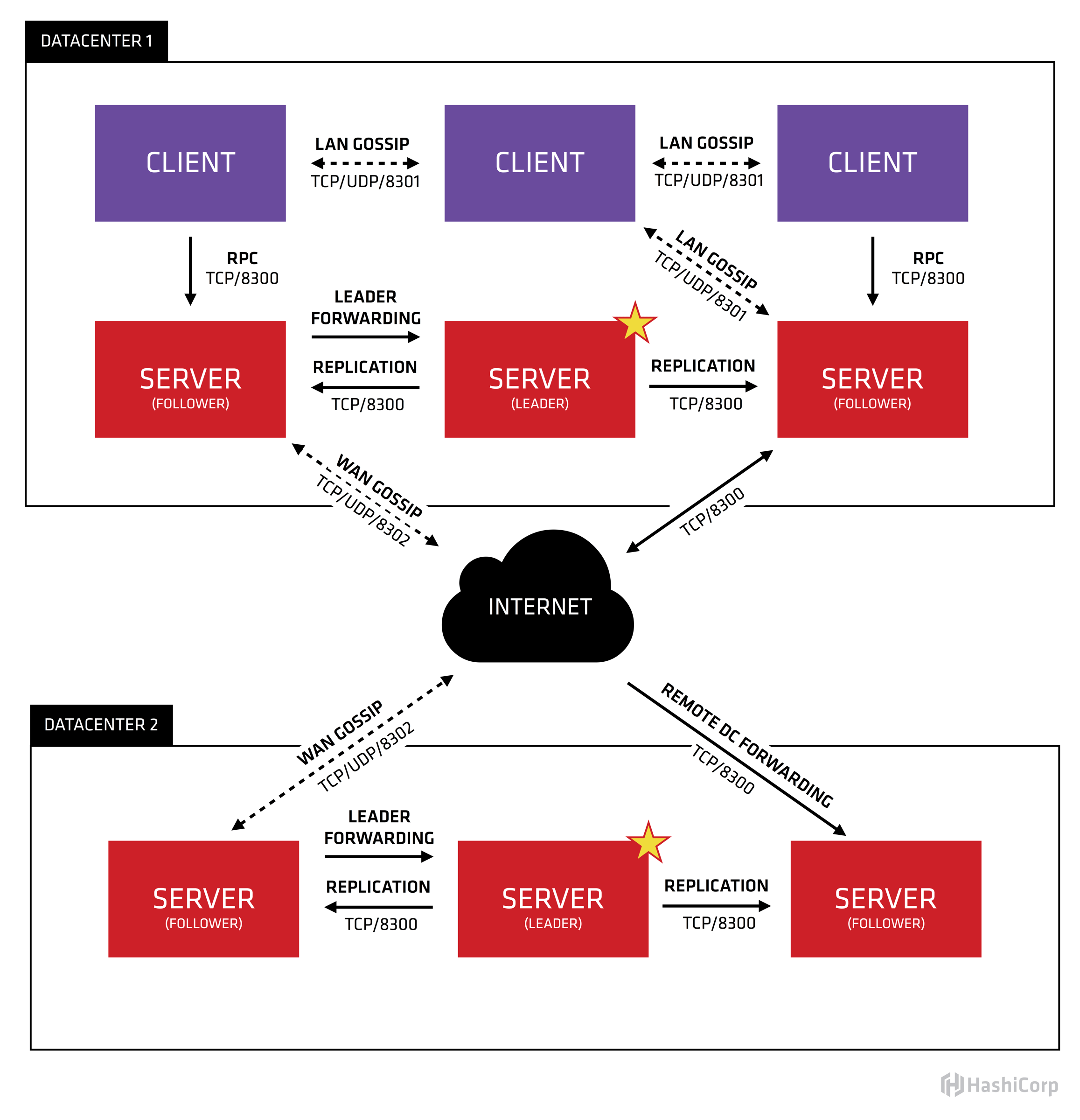
看得出一个Consul集群是由N个Server和M个Client节点组成的。
- Client节点:使用的client模式,该模式下可以接收服务的注册请求,但是会把请求转发给Server节点,自身不做处理,并且不持久化在本地
- Server节点:使用server模式,处理注册请求,将注册信息持久化到本地,用作故障恢复。
- Server节点分为Leader和Follower两个身份,Leader负责监控Follower,同步注册信息给所有的Follower,一个集群中只能有一个Leader
- Server之间通过RPC消息通信,Follower不会主动发起RPC请求,只会有Leader或选举时的Candidate主动发起
- Follower节点接收到RPC请求后,会将请求转发给Leader节点,由Leader节点处理后进行相应的ACK,请求分为事务型和非事务型,非事务型的请求由Leader节点直接响应,事务型的请求
- 集群一般推荐3或5个节点比较合适,因为Raft选举时,4和3、5和6的结果是一样的
Gossip是什么
从架构图中发现有一个Gossip,一个DC中涵盖了两个Gossip池,LAN池和WAN池,为什么会有Gossip,因为Consul是建立在Serf基础之上的,Gossip由Serf提供,Gossip是一个去中心化的协议。Consul中用Gossip维护节点关系,告知当前节点集群中还有哪些节点,其他节点的身份,是Follower还是Leader。
- LAN Gossip:局域网内唯一,LAN池是用于局域网内的节点消息广播,Consul的Client和Server节点全部都在LAN池中,LAN池中的客户端可以自动发现服务器,不需要进行过多的配置,LAN池能保证快速可靠的消息传播,比如Leader选举。
- WAN Gossip:WAN是全局唯一的,无论属于哪一个DC,所有Server应该加入到WAN中,由WAN提供信息让Server节点可以执行跨数据中心的请求。
工作原理
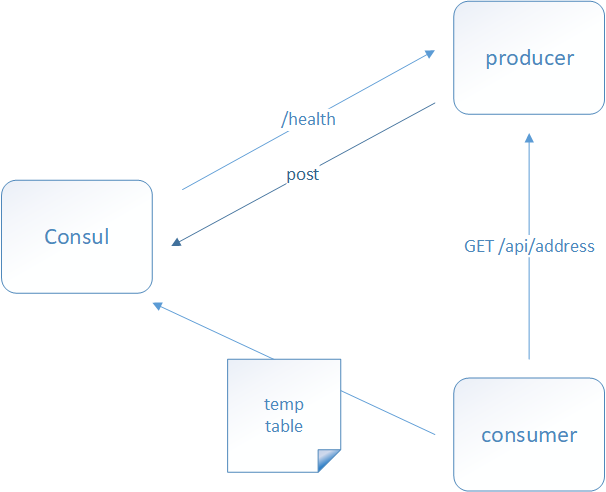
- Producer启动之后,会向Consul注册中心发送一个POST请求,上报自己的id、name、ip、port、健康检查接口、心跳频率等信息
- Consul接收到Producer上报的信息之后,根据上报的心跳频率和健康检查接口对Producer进行健康检查,检验Producer是否健康
- Consumer启动之后,会从Consul拉取Producer的列表缓存在本地,后续的请求都会从本地选举发出,使用RestTemplate发出请求的时候,每次都会从Consul同步一下服务者信息。
Leader选举
一个DC可以有多个Server,但是只能有一个Leader,Leader基于Raft算法进行选举,在Leader选举过程中,整个集群都无法对外提供服务。
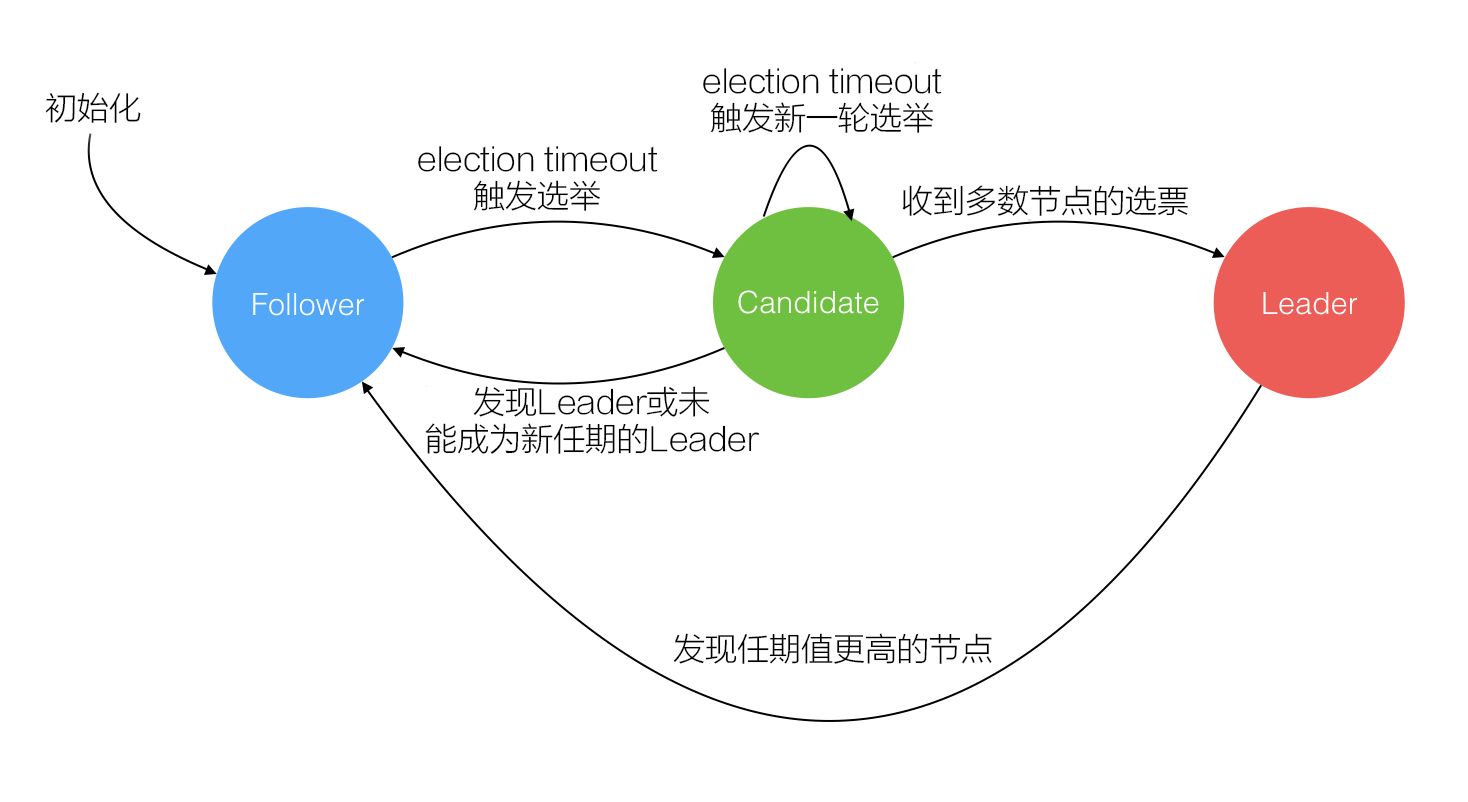
节点的身份有Follower、Candidate、Leader三种,所有的节点在初始化的时候都为Follower,节点加入到LAN Gossip池后,由Raft协议的Leader-Follower模式进行Leader选举。
-
概念
- Leader:集群中仅有一个,处理客户端所有的请求,遇到事务型的请求时会在本地处理后再生成同步日志,由Gossip通知到各个Follower节点进行同步
- Follower:所有节点的初始状态,正常集群中可以有多个Follower,不处理任何请求也不发送任何请求,只响应来自Leader和Candidate的请求,当接收到客户端发来的请求时会自动将请求转发给Leader节点处理
- Candidate:Follower超过选举器时都未收到来自Leader的心跳时,自动转换身份为Candidate,并根据Raft算法执行新一轮的Leader选举
- Election Time(选举超时时间):每一个节点都维护着自己的选举计时器,这个计时器的值需要大于心跳间隔,Follower收到Leader的心跳请求后会重置选举计时器,如果这个计时器归零了,则将节点身份转换为Candidate,并向其他节点发送投票。设置选举计时器主要是为了防止因为网络抖动等问题而引起心跳消息丢失,不然可能一旦心跳丢失了就立刻进入选举
- Heart time(心跳超时时间):Leader向Follower发送心跳的时间间隔
- Term(任期):任期是一个全局递增的数字,没进行一次选举,任期数就+1,每个节点都记录该值
-
Raft算法
Raft是一个共识算法,也就是当大多数对某个事情都赞同的情况下执行该事情,主要为解决分布式一致性的问题。Raft算法是从Paxos的理论演变而来,Raft把问题分解成领导选举、日志复制、安全和成员变化
- 领导选举:集群中必须存在一个Leader节点
- 日志复制:Leader节点接收并处理客户端的请求,然后将这些请求序列化成日志再同步到集群中的其他节点
- 安全性:已经被Raft状态机记录过的数据,就不能被再次输入到Raft状态机中
-
Leader选举过程
-
选举过程
在节点刚开始启动时,初始状态是Follower状态。一个Follower状态的节点,只要一直收到来自Leader或者Candidate的正确RPC消息的话,将一直保持在Follower状态。Leader节点通过周期性的发送心跳请求(一般使用带有空数据的AppendEntries RPC来进行心跳)来维持着Leader节点状态。每个Follower同时还有一个选举超时(Election timeout)定时器,如果在这个定时器超时之前都没有收到来自Leader的心跳请求,那么Follower将认为当前集群中没有Leader了,将发起一次新的选举。
发起选举时,Follower将递增它的任期号然后切换到Candidate状态。然后通过向集群中其它节点发送RequestVote RPC请求来发起一次新的选举,一个节点将保持在该任期内的Candidate状态下。
-
选举过程中可能遇到的问题
-
该Candidate节点收到超过半数以上集群中其它节点的投票赢得选举
如果Candidate节点收到了集群中半数以上节点的投票,那么此Candidate节点将成为新的Leader。每个节点在一个任期中只能给一个节点投票,而且遵守“先来后到”的原则,这样就保证每个任期最多只有一个节点会赢得选举成为leader。
-
收到任期号比当前节点任期号不一致的请求
- 比当前节点任期号小:说明当前集群已经进入了下一轮选举,则自动拒绝收到的请求,继续保持在Candidate状态
- 比当前节点任期号大:说明集群中已经存在了Leader,节点从Candidate切换到Follower
-
选举后没有任何一个节点成为Leader
本次选举未选举出Leader,则将集群中的任期号+1,再次进行选举
-
-
SpringCloud使用Consul
-
安装并启动Consul Server
1
./consul agent -dev
-
创建SpringCloud项目
- 服务提供方
1
2
3
4
5=7702
=consul-demo
=127.0.0.1
=8500
=/health1
2
3
4
5("/health")
public String health() {
System.out.println("----health check----");
return "hello consul";
}- 服务调用方
1
2=18090
=consul-demo-client1
2
3
4
5
6
7
8
9
10
11
12
public RestTemplate restTemplate() {
return new RestTemplate();
}
private RestTemplate restTemplate;
("/hello")
public String hello() {
return restTemplate.getForObject("http://consul-demo/health", String.class);
}- 两个项目启动后,查看服务注册情况:http://127.0.0.1:8500/
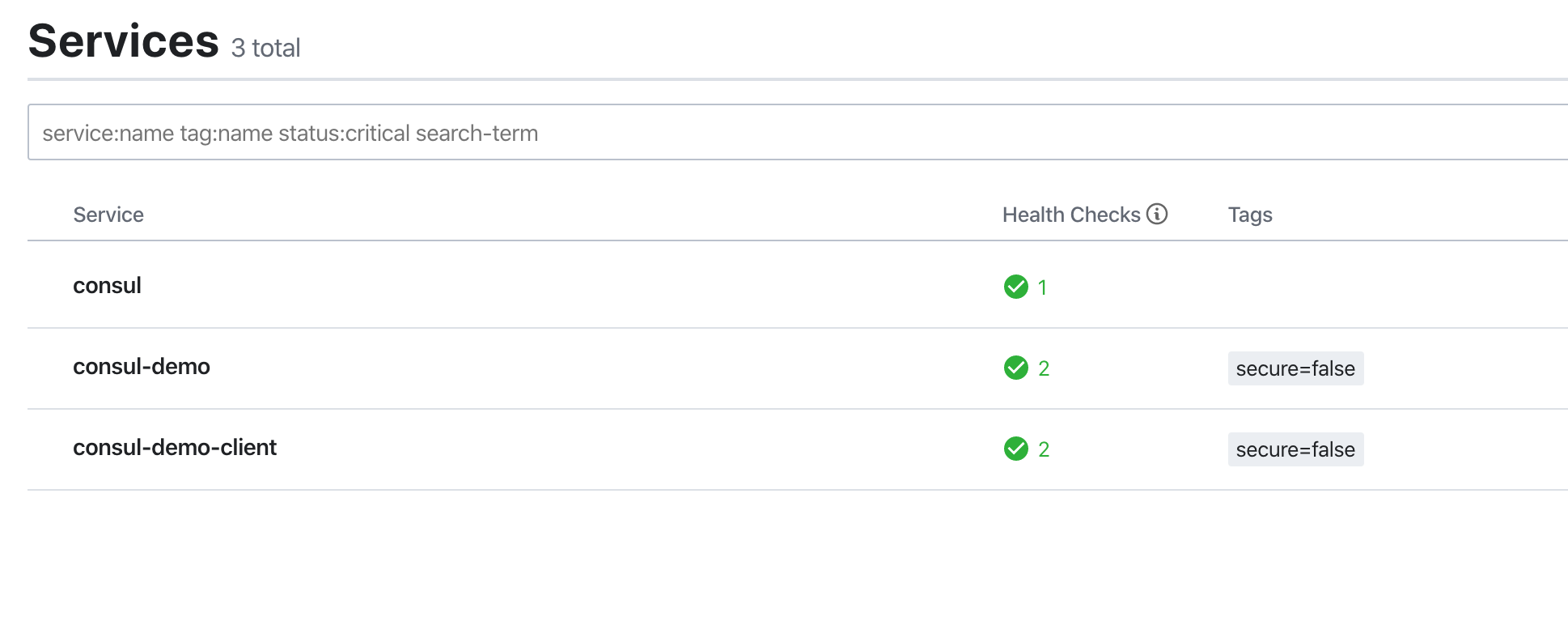
访问接口测试:http://127.0.0.1:18090/hello