前言
了解MySQL索引结构的基本都知道索引BTree类型是用B+树的数据结构,单列索引的结构我们很容易理解,二级索引的每个叶子节点只存储主键关键字外的一个数据,查询起来也很容易在非叶子节点进行大小值判断,最终找到叶子节点
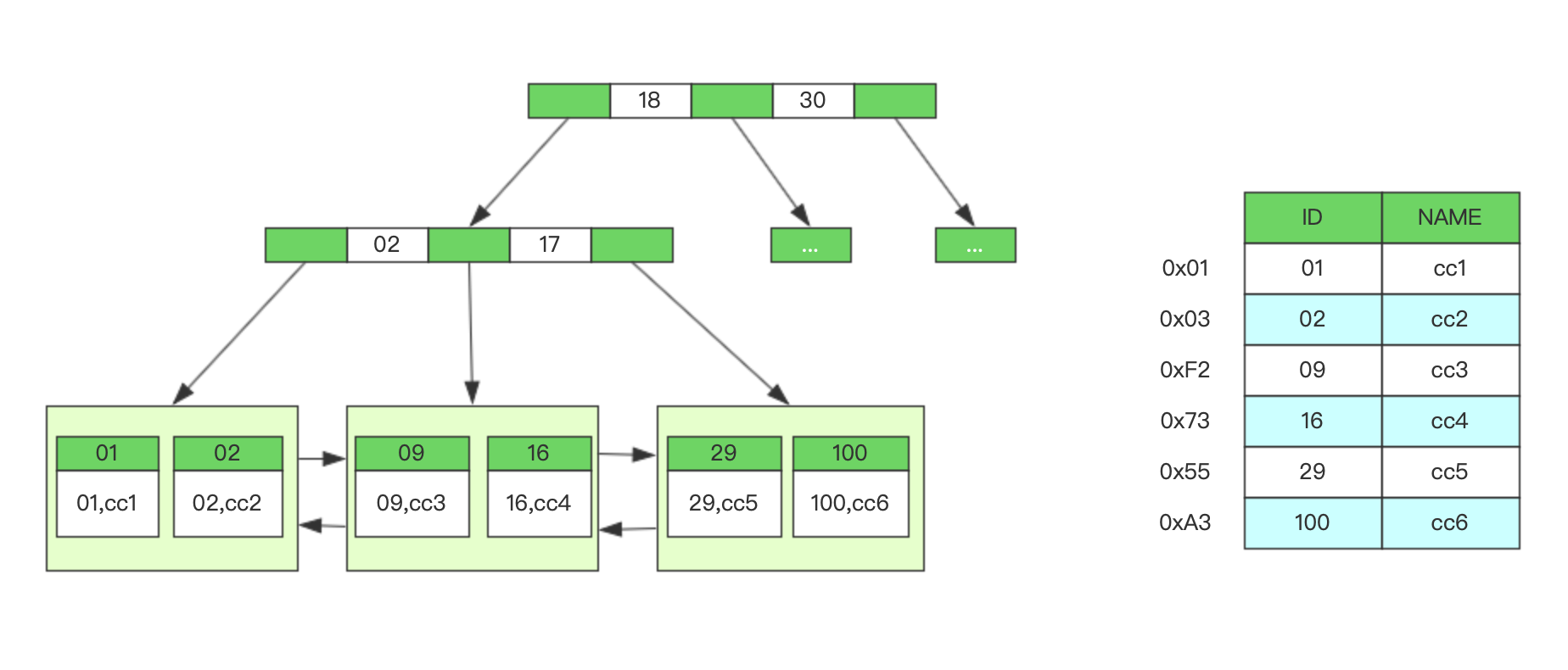
对于多列组合索引,存储结构也是B+树,那么非叶子节点和叶子节点都存储的是什么内容?
二级组合索引
对于组合索引,需要遵循断桥原则(最左匹配原则),例如(a, b,)可以满足a,a、b,我们根据这个原则反推一下二级组合索引的存储规则:
- 叶子节点应该是线性排列,并且每个节点的数据排列顺序和创建索引字段的顺序一致
- 叶子节点排列顺序应该是先按照a进行排序,排序完成后再按照b进行排序,所以应该是a是全局有序,b是a中有序,如果列数更多的情况下,下一列都相对于前列有序。
- 非叶子节点存储完整的索引关键字信息,排列规则和叶子节点一致
- 整体查询使用二分法
根据上述推断,我们基本可以判定二级组合索引的数据结构图了
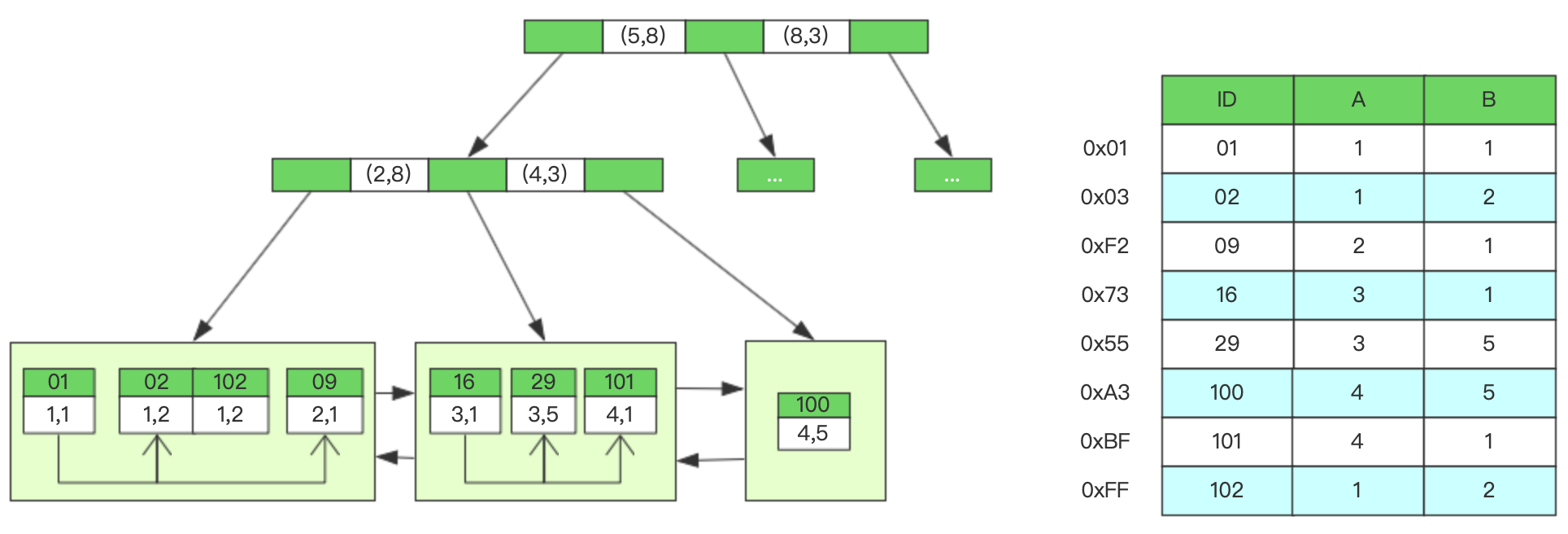
上面我们进行了规则反推,也根据反推总结出了简单的组合索引数据结构图,那么我们来验证一下上述推论:
- 因为索引遵循断桥原则,B+树是顺序且极限二分查找的方式进行遍历,所以在进行B+树遍历的时候从左到右进行匹配,并且我们创建索引的目的是为了提升查询效率,如果每个节点中数据和索引的字段顺序不一致,各执己见,那么在查询的时候还要判断当前节点的某位数据对应了索引的哪个字段,效率会更低,所以推论1是可信可靠的。
- 根据图中叶子节点的数据可以看出,所有的数据都是按照列A进行排序的1、2、3、4,B列的顺序为1、2、1、5、1、5,B列全局是无序的,这就尴尬了,如果我们仅按照列B去查询,在索引中匹配的时候岂不是很麻烦,或者说压根儿就无法匹配,这也就明白了为什么仅使用到列B的时候不会走索引了,那仅使用A的时候可以走索引是因为列A在索引树中相对于全局是有序的,所以可以根据列A进行二分查找和定位。由此可见推论2也是可靠的。
- B+树的非叶子节点存储的是索引关键字的数据信息,并且根据推论2的结果可以验证推论3也是正确的。
- B+树是使用二分法进行查找的,所以推论4是正确的。
总结
我们根据B+树的特性、索引的断桥原则和单列索引存储特性三个方面反推组合索引的数据存储结构,并验证了我们的推论,这仅仅是串一串的推论,可能不靠谱,哈哈~