[TOC]
一、前言
1.1 工具
1.2 命令
二、操作影响
当机器负载过高时,对于机器所有的操作基本都会变慢,最显著的表现就是登录服务器都会变得很慢,好不容易登录上去了,敲一个命令都要响应半天,尤其是当使用tab键进行命令补齐时,操作窗口直接卡住了;同时我们还会发现,不仅仅是服务器的响应变慢了,网络、IO也变慢了,然后连带着部署在机器上的服务的响应也变慢了(很大可能是它自己引起的)。
既然机器负载过高的影响这么大,我们就来看看怎么盘它。
三、系统负载
系统负载也叫CPU负载,代表着机器CPU的压力,我们首先要知道负载是什么,然后再知道怎么查看负载,看到了负载我们还需要知道是否过载。我们先来说下负载是什么:负载表示当前机器活着的可执行队列(执行中+待执行)的长度,长度越多,表明机器越忙,负载则越大,也可以理解为当嘴塞满了之后还一直往嘴里塞东西,如果一个进程满足以下条件则其就会位于运行队列中:
- 它没有在等待I/O操作的结果
- 它没有主动进入等待状态(也就是没有调用
wait) - 没有被停止(例如:等待终止)
3.1 查看负载
查看负载的方式有多种,我们可以使用top、uptime、w、vmstat等命令进行查看,前三个命令的输出格式都一样,仅vmstat我们可能需要稍微分析一下
- 先来看下前三个的输出
1 | 00:55:56 up 136 days, 1:40, 1 user, load average: 0.55, 0.33, 0.26 |
这是一整行数据(这不废话么),这一行数据分了四个部分:
00:55:56:系统当前时间
up 136 days, 1:40:系统自上次启动后持续运行时长
1 user:当前系统在线用户
load average: 0.55, 0.33, 0.26:系统1分钟、5分钟、15分钟的平均负载信息(在CPU上运行或者等待运行多少进程)
在这里主要关注第四部分,也就是load average
- 再来看
vmstat的输出
1 | procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- |
这个命令输出的内容详细的记录了当前正在执行的任务数以及被阻塞的任务数,并且输出了内存、swap区、io、cpu和系统信息。
- 总结一下
查看机器负载的简单方法已经介绍完了,单从简洁角度看的话,使用w和uptime输出的内容更加简洁明了,而vmstat输出的内容多样且详细。平时我们第一步大多是快速查看系统1分钟、5分钟、15分钟内的平均负载,所以还是前三个命令使用的多,需要查看具体详细内容的话,再使用最后一个。
3.2 过载判定
当使用命令把负载输出之后,还需要对负载数据进行判断,要能够知道什么情况下的负载是正常的,什么情况下的负载是过载的,也要能判断出过载程度如何。
一般根据CPU的数量去判断系统负载是否超载,目前应该没有公司会使用单核的服务器了吧,我们这里也说一下。我们可以把CPU当成是高速公路收费站的人工收费口,进程就是路过的一辆辆车:
-
单核服务器
单核服务器就是只有一个可用的人工收费口,这时所有的车辆都需要从这一个收费口通过(这是一句废话)。
- 当有牌照的车通过时,车只需刷一下卡交个费就可以从收费口通过,每分钟可以通过多辆车,这时负载就会很低;
- 当使用临时牌照的车通过时,需要先出示通行卡,然后再出示临时牌照,收费员刷了卡,然后调用车辆进入高速时的监控照片,随后查验车辆临时牌照,然后再收费…这么一系列操作完成之后,一般一分钟就过去了,这时单收费口的负载就是1;
- 如果车辆在通过时出现了故障,那么这个时候整个通道都会被堵塞住,后面的车辆全部处于待通过状态,负载就变得非常高
-
多核服务器
当车流量激增时,一个收费口显然无法满足通行需求,收费站调控室会下达开放其他收费口的指令,利用多个收费口来将车辆分流,提升吞吐量。那么当CPU不够的时候当然也可以通过增加CPU来提升进程队列的吞吐量,这也就是我们所说的多核机器,一个CPU代表一核(这话说的好弱智)。我们还拿上面三个例子来说,以4核为例,和单核相比,吞吐量提升了4倍,负载降低了4倍左右,这就不用解释了吧,如果不懂,那就去看看小学二年级数学吧。
通过上面的不太恰当的例子可以总结出,当负载低于CPU核数时,服务器的负载是正常的,然后越低越好,正常情况下,一台正常的机器的负载一般在1.0以下,那么负载到底超过多少算是过载了呢?从上面的小栗子我们可以看出来,如果每一个CPU每分钟都处理1个进程,4核机器在1分钟内的负载就是4,服务器每一个CPU都一直处于忙碌中,毫无休息的时间,长期如此,机器会扛不住,短时间的可以接受,5分钟以上就需要好好排查一下了,理论上可容忍的最高负载为:1.2 * CPU核数
四、监控工具
如果机器长时间负重前行,就会变得很累,所以要能及时发现并帮它把负重降下来,所以我们要对服务器做相应的指标监控,给每一个监控设置阈值,当指标超过阈值时能够主动的给运维人员发送通知。
4.1 监控选型
监控的方式有基于Prometheus的node_exporter,有界面炫酷的Netdata,也可以自己写shell脚本,当然也有很多其他的工具,这里我们主要介绍这三类:
- Prometheus主要是指标的采集和告警,界面化并不是很好,一般需要搭配Grafana进行可视化,而对于告警来说,Prometheus可以通过集成Alertmanager来实现告警,也可以在Grafana中配置Alert来达到告警的目的。Alertmanager完全配置化操作,并且对重复消息及告警规则比较人性化,Grafana则为界面化操作,两种选其一即可。
- Netdata可视化页面非常炫酷,但是需要访问国外资源,不能科学上网的话,不推荐,下面会告诉怎么使用国内资源。
- shell脚本编写起来也很简单,并且方便,定制化强,可以根据自己的实际需求设置告警,但是对编写shell脚本的能力有一定的要求
对比下来看,使用Prometheus+Alertmanager+Grafana是容易上手的,我们先来重点看下怎么使用它,后面会将Shell脚本贴到文末。
4.2 配置监控
Prometheus、node_exporter、Alertmanager和Grafana的安装步骤就不单独做说明了,自行谷歌吧,我们主要解释一下怎么使用node_exporter采集信息,然后用Alertmanager配置告警、用Grafana配置告警。
-
node_exporter使用很简单,官网下载下来,然后启动即可,但是要注意的是机器的
9100端口不能被占用,因为它默认使用的端口是9100,也可以通过启动参数进行修改,见下方。exporter采集关于机器的很多指标,关于机器负载性能这块只需要关注这几个参数:1
2
3
4
5
61分钟平均负载
node_load1 0.11
5分钟平均负载
node_load5 0.11
15分钟平均负载
node_load15 0.04 -
Prometheus只需要定期通过
node_exporter的url来进行数据采集,配置内容如下:1
2
3
4
5scrape_configs:
# 采集node exporter监控数据
- job_name: 'node_exporter'
static_configs:
- targets: ['ip:9100'] -
Alertmanager与Prometheus配合实现告警的通知,Alertmanager是Prometheus官方提供的插件,安装办法不做介绍,配置信息主要是在Alertmanager的配置文件
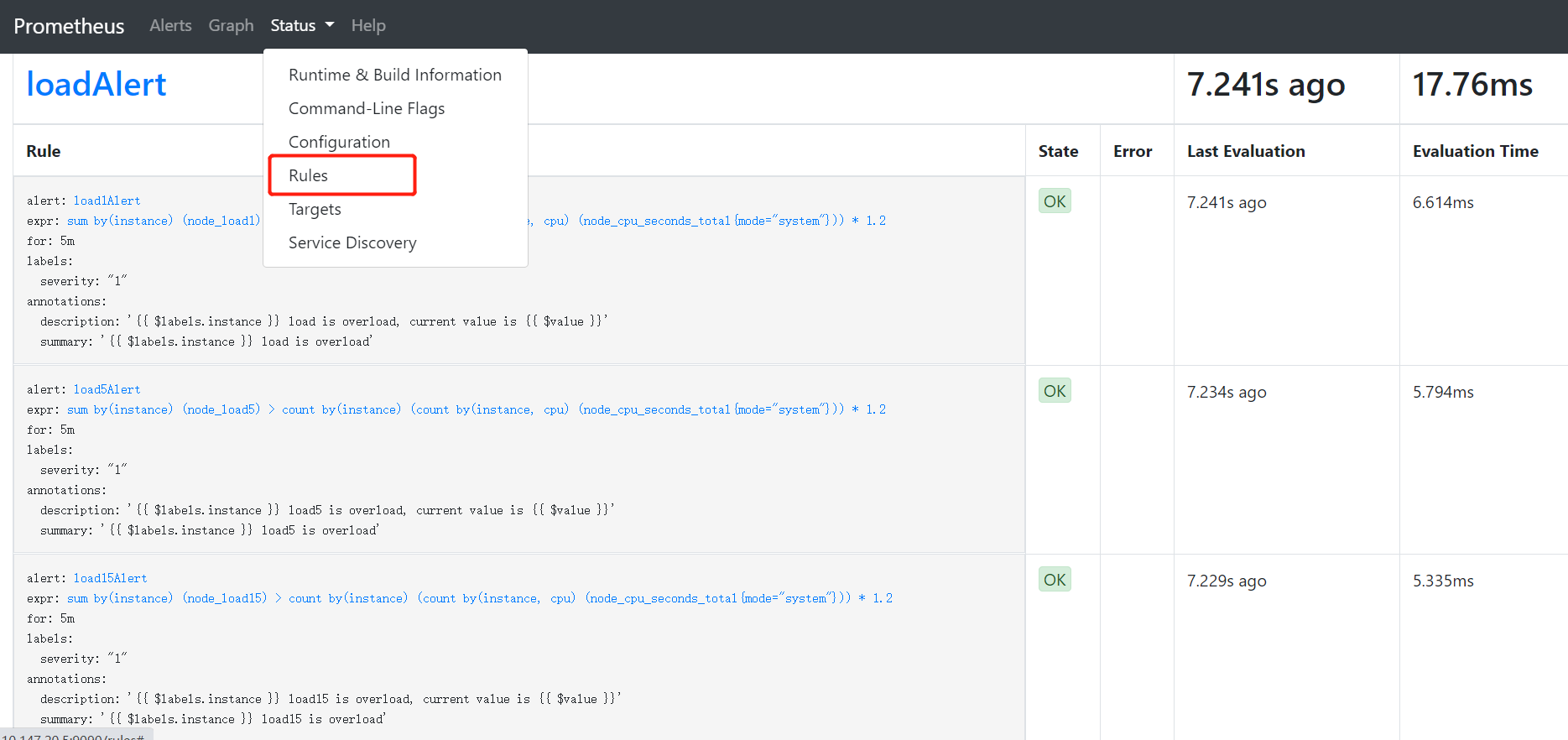
alertmanager.yml中。Alert有三个阶段,分别是Inactive、Pending、Firing,分别表示告警规则的三个阶段,当监控指标处于正常情况下,告警规则处于Inactive阶段,在Prometheus的web页面可以查看相关状态http://ip:9090/alerts: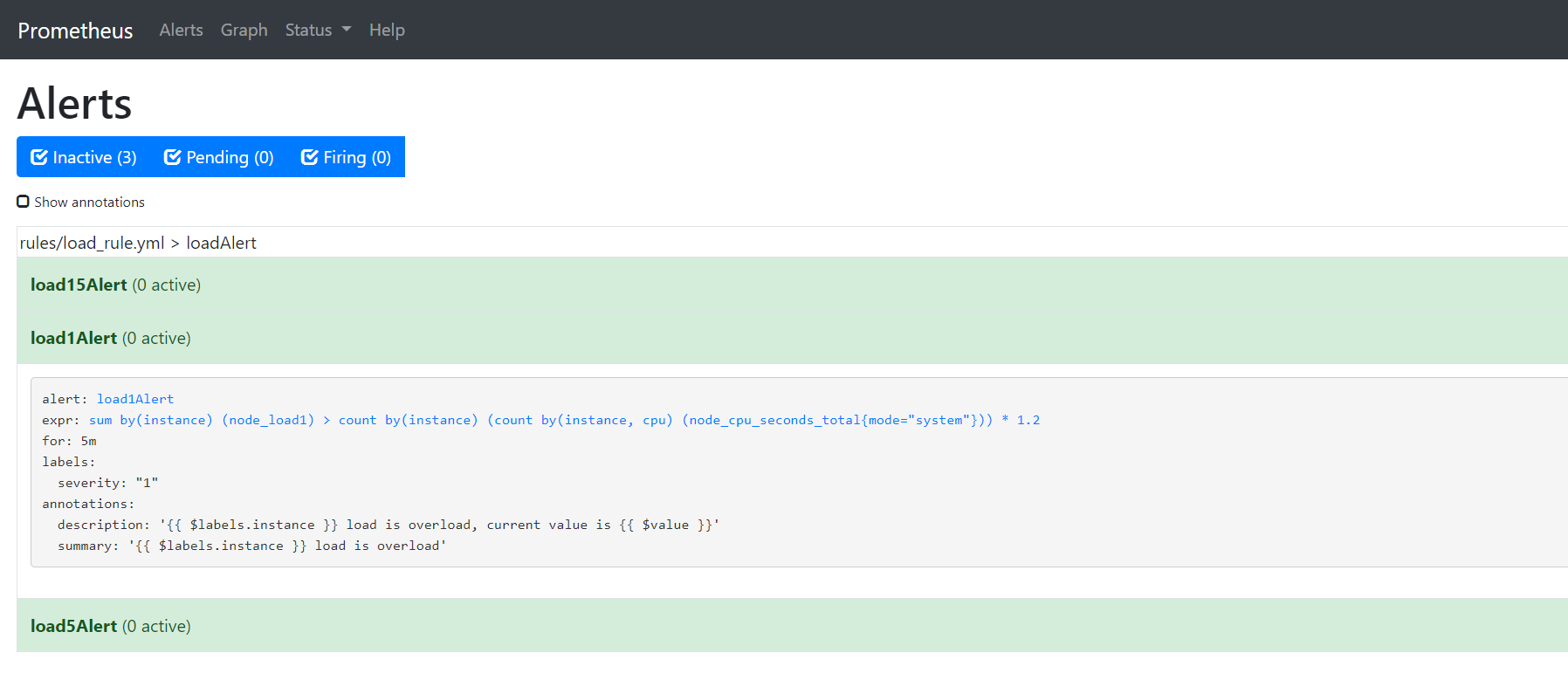
说完了
Inactive,接下来就是它的邻居Pending,这玩意儿是代表着啥呢?我们当监控的值满足条件时,是否应该立即发送告警呢?如果你需要这样的操作,当然也可以,但是一般我们监控任何事情都需要一个观察期,防止出现误报、乱报的情况出现,提高告警准确性。配置信息中for关键词就是持续观察的作用,意思是当指标异常时,持续观察指定时长,比如上面图中指定的5m代表持续观察5分钟,如果5分钟之后指标依然异常,那么就触发告警,那么在这五分钟之内,告警规则的状态就处于Pending状态;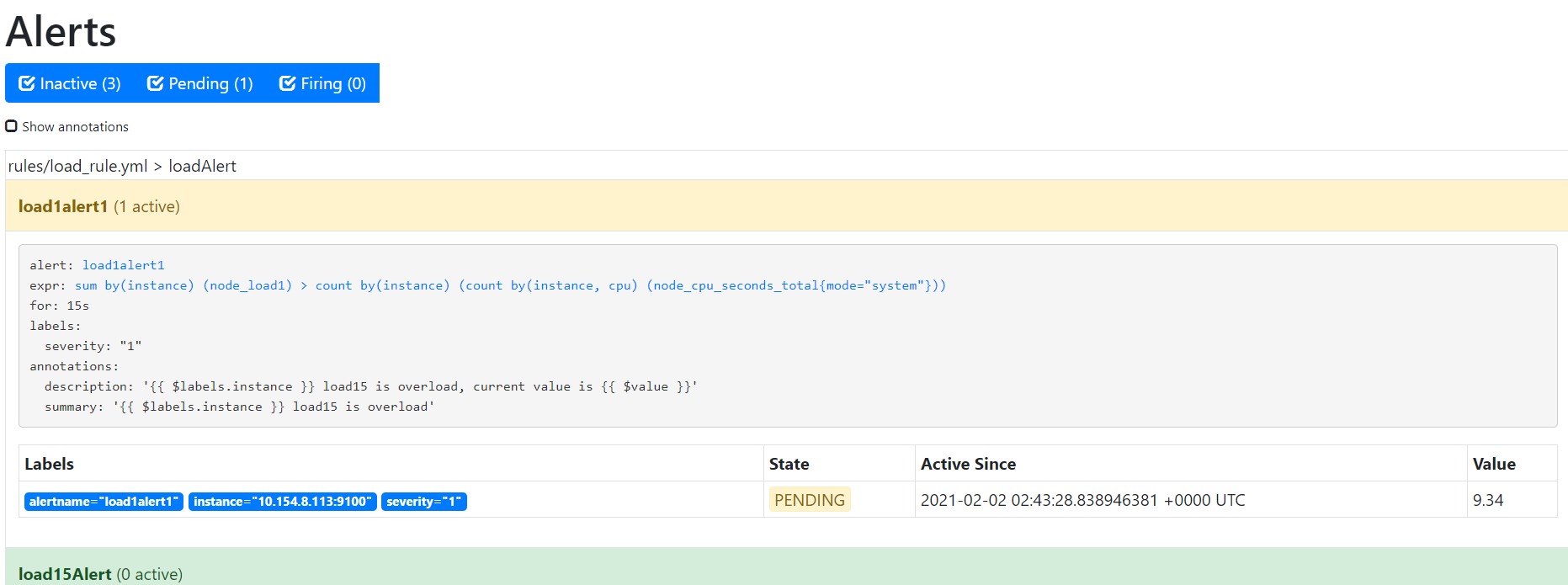
观察期内指标恢复正常,则回溯到
Inactive,观察期后指标依然异常,则触发告警通知,并将规则状态修改为Firing(莫名的想大喊:二营长,你他娘的意大利炮呢!?)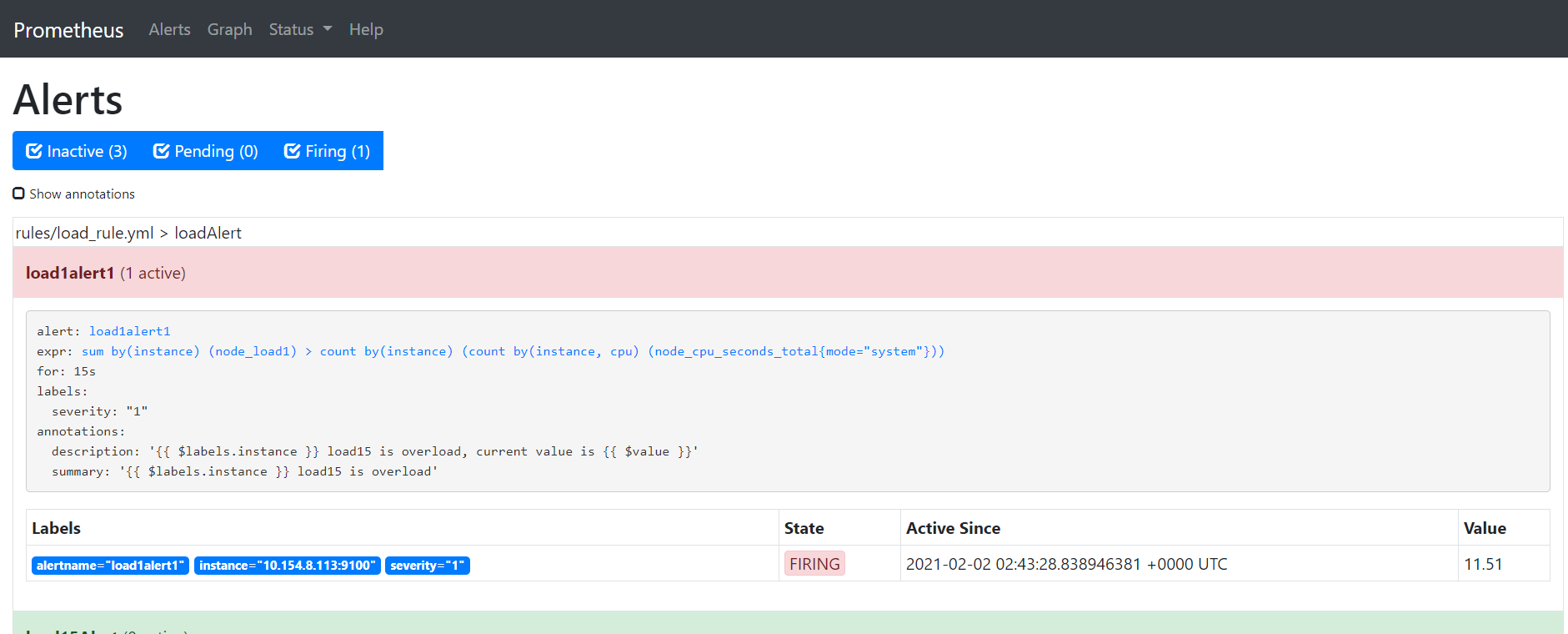
-
Grafana配置就比较简单了,只需要配置一个数据源就可以了,目标地址指向Prometheus即可,就不展示了。
4.3 告警设置
告警可以通过Prometheus或者Grafana实现,Grafana设置比较简单,全部都是可视化的,Prometheus则稍微复杂一点,并且需要搭配Alertmanager来实现,Alertmanager支持多种告警方式:邮件、 即时通讯软件(如Slack、Hipchat)、移动应用消息推送(如Pushover)和自动化运维工具(例如:Pagerduty、Opsgenie、Victorops),我们主要拿邮件来说一说。
4.3.1 Prometheus告警设置
Prometheus的告警由两部分组成,一部分是告警规则设置,也就是AlertRule,定义在prometheus.yml文件中的rule_files标签下;另一部分就是Alertmanager,具体的告警处理器,Prometheus会周期性的对告警规则进行计算,如果满足条件就会向Alertmanager发送告警信息,盗用一张架构图:
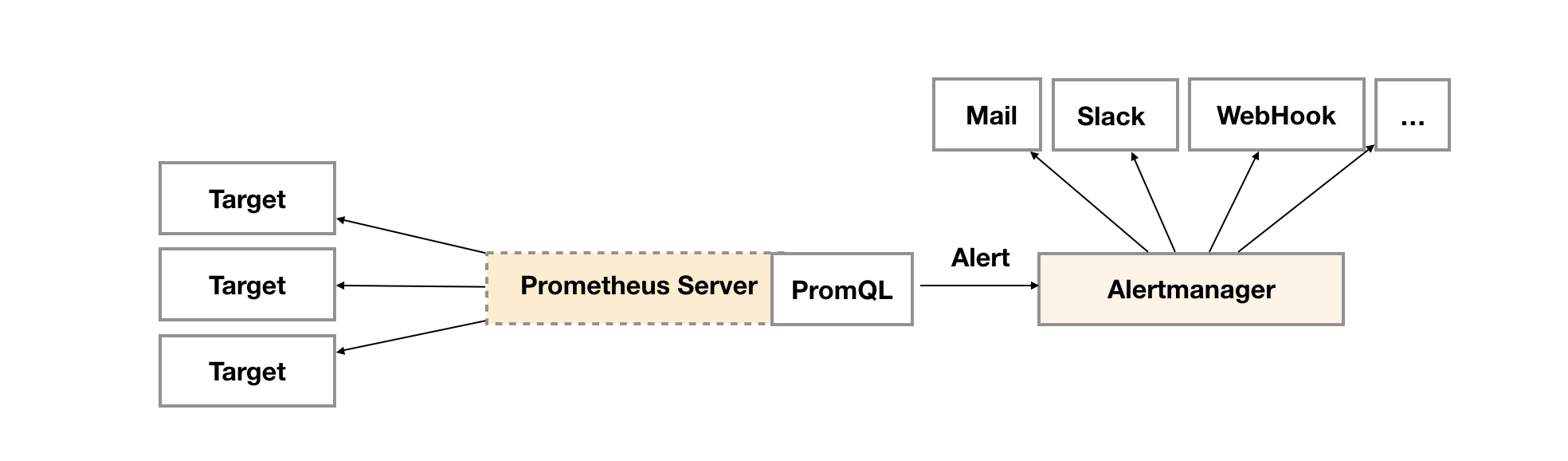
如果需要让Prometheus达到自动告警的目的,需要配置两块内容,一个是Prometheus的prometheus.yml,另一个是Alertmanager的alertmanager.yml,两者各司其职,Prometheus进行数据采集、分析计算、通知Alertmanager,Alertmanager执行告警,具体配置如下:
prometheus.yml
1 | # 配置Alertmanager |
rules/basic_rule.yml
1 | groups: |
alertmanager.yml
1 | global: # 全局参数配置 |
4.3.2 Prometheus智能预测
Prometheus内置了predict_linear(v range-vector, t scalar)函数预测时间序列v在t秒后的值,它基于简单线性回归的方式,对时间窗口内的样本数据进行统计,从而可以对时间序列的变化趋势做出预测,比如我们基于15m的样本数据,来预测主机5分钟负载是否在5分钟后过载,可以使用如下表达式:
1 | predict_linear(node_load5{}[15m], 300) < 0 |
4.3.3 Grafana告警设置
Grafana告警就比较简单了,在配置文件中设置告警发送邮件配置,然后在Grafana控制台http://ip:3000进行相关的配置,主要步骤是先到Grafana安装目录下找到conf/defaults.ini文件,修改如下配置:
1 | #################################### SMTP / Emailing ##################### |
修改完成之后重新加载该配置文件或者重启Grafana,在控制台左侧菜单中找到Alerting,进入后到Notification channels下新增一个通知channel,可依据不同的告警业务线配置各自的channel,channel中可以指定告警方式、告警处理人等信息
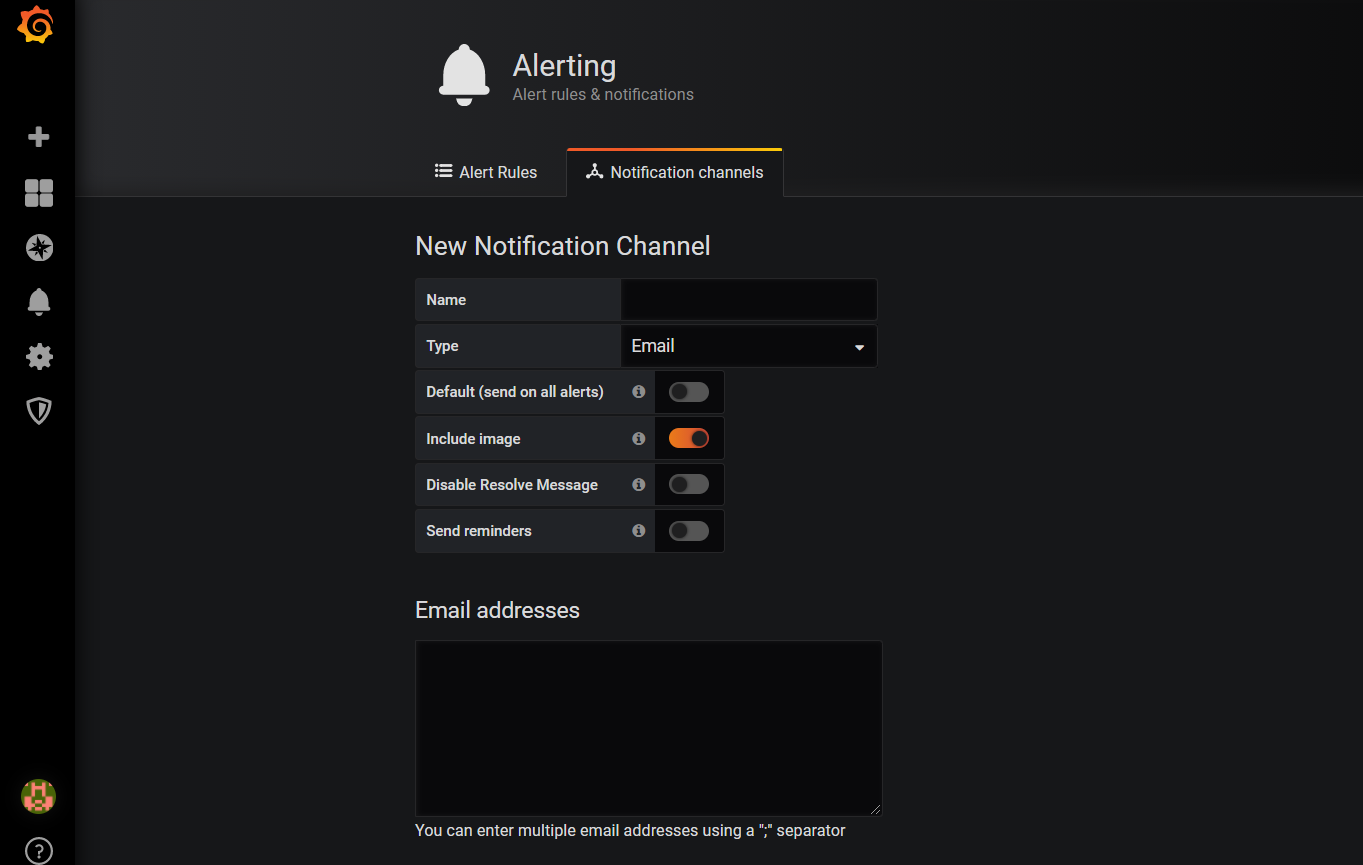
通知channel配置完成之后就可以愉快的配置我们的告警指标了:
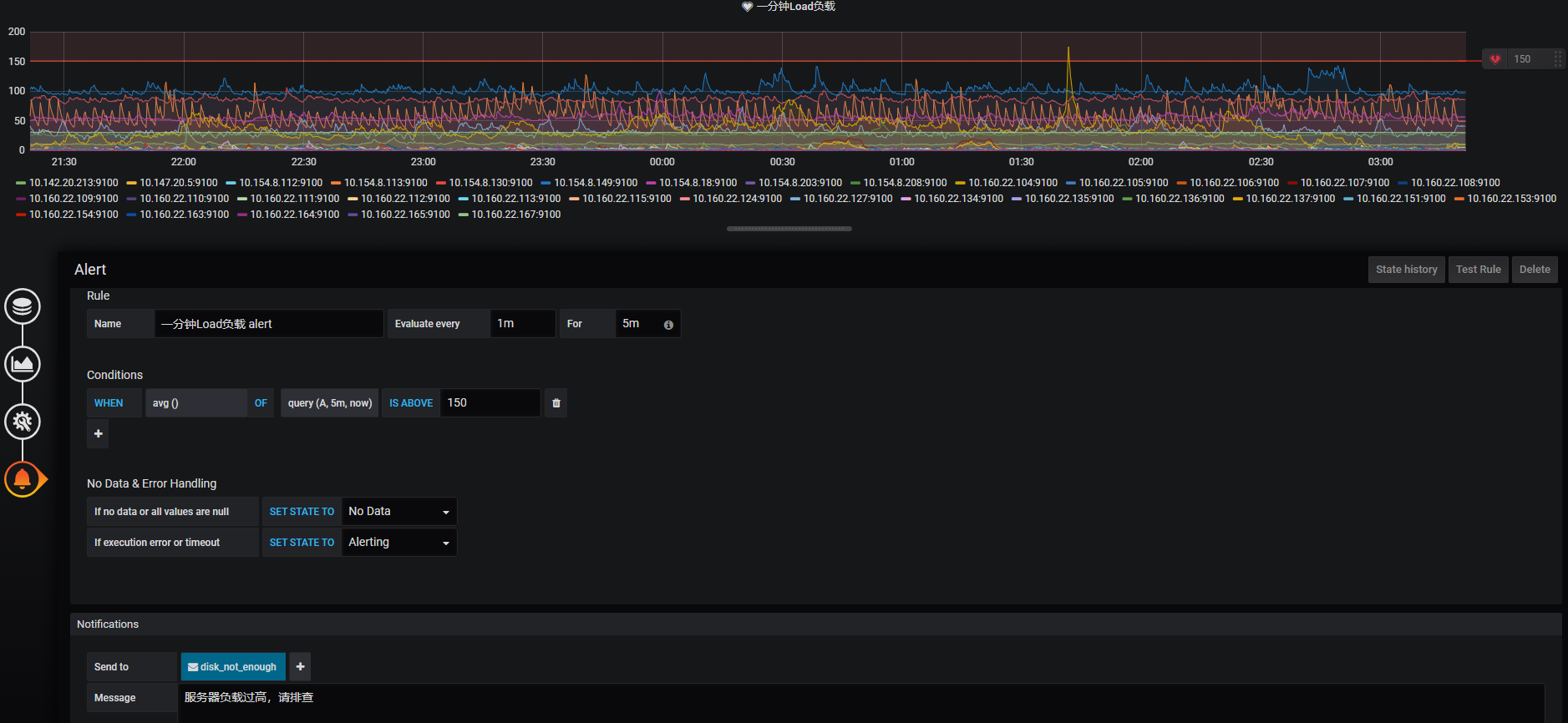
4.4 验证监控
我们配置了那么多监控,需要验证一下到底有没有用啊,如果没用的话,那我们配置这么多玩意儿干啥,为了测试,我们可以把CPU全都吃满,第十节有具体的使用方法,这里我们使用最简单的一种方式把机器所有的CPU资源都消耗殆尽cat /dev/urandom | gzip -9 | gzip -d | gzip -9 | gzip -d > /dev/null,然后等待系统邮件告警通知。
五、排查定位
上面讲了那么多监控的信息,实际上就是为了能让我们及时的发现机器负载故障,这是重点之一,另一个重点就是找出负载过高的原因,然后解决它,服务器负载主要受CPU、内存、IO、网络等因素的影响,下面重点说一下各自的排查手段和问题定位方法。
5.1 CPU排查
负载过高一般都是由CPU引起,但是CPU会受系统硬件瓶颈和用户进程的影响,所以我们首先需要找出到底是什么原因造成的CPU飙升,第一步当然是要排查一下用户进程,因为系统硬件一般不会出问题,如果是硬件问题,那么应该老早就出问题了,不会等到现在,并且突然出问题的可能性也比较小,所以第一步还是直截了当的去看用户进程吧。
5.1.1 用户进程排查
可以使用top命令查看用户进程对CPU的资源使用情况,命令使用方式和介绍可以使用man top查看,top命令详细分析查看**《10.1小节》**,top命令是Linux下常用的性能分析工具,能够实时显示系统中各个进程的资源占用状况:
1 | 使用-c查看用户进程详细的COMMAND信息 |
我们需要关注%CPU,负载高的时候,该值可能是100%的好几倍,但并不是值很大就一定是它引起的,还需要看服务器CPU数量和CPU使用率分布,比如服务器是8核的,某进程CPU的使用率为300%,这时候可以按数字键1查看每一个CPU的使用率:
1 | Cpu0 : 55.0 us, 0.3 sy, 0.0 ni, 98.0 id, 80.0 wa, 0.0 hi, 0.3 si, 0.3 st |
从指标数据上看到每一个CPU的使用率都没有超过60%,说明CPU的利用率还是蛮高的,这个时候不用担心,可以持续关注。但是一旦用户进程的CPU使用率把每一个或者某几个CPU都吃满了,那就要好好的排查一下了,如果用户进程是java进程,那么直接跳到第六章吧,有详细的排查介绍;如果是其他进程,则根据具体的进程类型使用对应的命令进行排查,基本也逃不过进程->线程->堆栈->代码这套流程。
5.1.2 硬件排查
硬件排查略了,不会
5.2 内存排查
查看内存使用情况主要通过free -h命令来查看,我们查看的输出结果如下:
1 | total used free shared buff/cache available |
available还有6.8G,可用内存充裕,看来不是内存的问题。若内存仅剩几M,那么就可以继续使用top命令查看%MEM指标项找出内存占用比例最大的进程进行排查。
在使用free命令查看内存使用率时,有时可能会出现buff/cache占用特别高的情况,说明系统中有进程曾经读写过文件,这个不打紧,这部分内存是可以当空闲来用的,当内存即将用完的时候,Linux内核会自动回收这部分内存。但是回收内存一定伴随着系统IO飙升,也可能会出现内存回收不及时导致进程内存续命失败,所以除了依赖于内核之外,我们还可以手工进行清理,并且可以将清理任务设置到crontab中。
1 | 表示清除pagecache。 |
可以将该脚本通过crontab设置20分钟执行一次,及时清理cache的内存占用。
1 | */20 * * * * sh /data/clean.sh |
5.3 IO排查
5.3.1 磁盘性能排查
我们从5.1.1小节中能看出来,wa值特别高,该指标表示的是磁盘IO等待时间,也就是说磁盘性能越高,IO等待时间将会越短,那么wa值就越小;相反,如果wa过高,则表示磁盘读写出现了性能问题,这时可以通过iostat命令进行详细的排查,该命令默认是需要自己安装的,安装命令yum install -y sysstat。
1 | [root@cc ~]# iostat -x 2 1 |
对于iostat命令的详解请查看**《10.9小节》**,通过输出我们可以详细的看出机器每一块磁盘的性能指标,主要关注r/s、w/s、rkB/s、wkB/s、r_await、w_await几项指标,代表着磁盘读写的各项性能,从上表中可以看出vdb磁盘的读性能略低,读等待时间较高,但写入性能蛮高,还是一块比较好的磁盘。
5.3.2 IO占用进程排查
在实际的工作当中,在知道了磁盘压力只会,还需要更深入的排查出到底是哪一个进程造成的IO压力过高,这时可以使用iotop命令查看进程的IO信息,根据输出信息进行相关排查:
1 | Total DISK READ : 0.00 B/s | Total DISK WRITE : 15.23 K/s |
我们通过对DISK READ和DISK WRITE两项指标得出进程的IO效率,然后再对进程做进一步排查。
5.4 僵尸进程排查
僵尸进程是指那些实际上已经死了,但还一直占用着一小部分资源的进程。如果系统中出现过多这类进程,对机器会是一个很大的隐患,所以正常情况下,我们还是需要及时处理掉这些僵尸进程。想要清除僵尸进程不是一件简单的事情,是不是想到可以用kill命令将其杀死?但是不要忘了僵尸本身就是已经死亡状态,所以不管使用多少次kill或kill -9,都不可能将一个已死进程再次杀死,它需要它的父进程来为他收尸,如果父进程没有安装SIGCHLD信号处理函数调用wait 或 waitpid() 等待子进程结束,也没有显式忽略该信号,那么它就一直保持僵尸状态,如果这时候父进程结束了,那么init进程会自动接手这个子进程,为它收尸,它还是能被清除掉的。但是如果父进程是一个循环,不会结束,那么子进程就会一直保持僵尸状态,这就是系统中为什么有时候会有很多的僵尸进程,并且系统还很友好的为僵尸进程加了副棺材[]。
那么僵尸进程就彻底没办法清除了吗?其实也不是,有两种方式能够结束掉它:
- 重启机器。但是代价有点大,毕竟机器上运行着很多不能中断的服务,贸然重启会造成一些不必要的影响。
- 杀掉其父进程。手动杀掉父进程,然后由父进程来回收子进程的尸首,这种方式不会影响到机器上的其他服务进程,此举甚妙。
六、Java进程解决
在排查过程中,如果影响机器负载的进程为Java进程,一般是由线程死锁、大文件读写等操作造成的,可以参照如下步骤进行相关的排查。
6.1 查看占用资源最高的Java进程
简单的使用top -c命令查看Java进程的CPU和Memory使用情况,找到%CPU和%MEM指标项较高的Java进程,得到进程的PID
1 | PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND |
6.2 查看进程中占用资源最高的线程
将上一步拿到的进程PID 390477继续深入查看进程内的线程信息,命令则使用top -Hp 390477
1 | PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND |
6.3 输出线程栈信息
通过上一步找到了资源消耗最大的线程,找到线程还不算完,接下来就要打印出线程的堆栈信息,
6.4 分析线程栈
6.5 缺陷解决
七、MySQL进程解决
7.1 查询processlist
通过命令show processlist
7.2 判定慢查询
7.3 查询死锁
八、其他因素解决
九、工具介绍
9.1 Prometheus
9.1.1 node_exporter设置
1 | node_exporter监听的端口,默认是9100,若需要修改则通过此参数。 |
启动之后请求路径为:http://ip:9100/metrics
#####9.1.2 Prometheus设置
Prometheus主要使用PromQL进行数据的分析和计算,PromQL的语法和函数不在这里讨论,可以到官网学习一下,我们主要看下prometheus.yml的配置
1 | # 配置Alertmanager |
#####9.1.3 Alertmanager设置
1 | global: |
- Grafana设置
9.2 Netdata
9.3 Shell
9.3.1 用脚本统计出来处于运行队列的进程
1 | !/bin/bash |
运行结果(R代表运行中的队列,D是不可中断的睡眠进程):
1 | Tue Feb 2 23:31:12 CST 2021 |
在load比较高的时候,有大量的进程处于R或者D状态,他们就是造成load上升的元凶
9.3.2 查CPU使用率比较高的线程小脚本
1 | !/bin/bash |
运行结果:
1 | Tue Feb 2 23:32:23 CST 2021 |
9.4 stress
1 | CPU |
9.5 lookbusy
1 | CPU |
十、命令介绍
10.1 top命令
1 | top - 23:59:34 up 141 days, 43 min, 1 user, load average: 0.11, 0.17, 0.18 |
第一行解释:
top - 23:59:34 up 141 days, 43 min, 1 user, load average: 0.11, 0.17, 0.18
23:59:34:系统当前时间
up 141 days, 43 min :系统开机到现在经过了2天
1 users:当前1用户在线
load average: 0.11, 0.17, 0.18:系统1分钟、5分钟、15分钟的CPU负载信息.
备注:load average后面三个数值的含义是最近1分钟、最近5分钟、最近15分钟系统的负载值。这个值的意义是,单位时间段内CPU活动进程数。如果你的机器为单核,那么只要这几个值均<1,代表系统就没有负载压力,如果你的机器为N核,那么必须是这几个值均<N才可认为系统没有负载压力。
第二行解释:
Tasks: 116 total, 1 running, 115 sleeping, 0 stopped, 0 zombie
116 total:当前有116个任务
1 running:1个任务正在运行
115 sleeping:115个进程处于睡眠状态
0 stopped:停止的进程数
0 zombie:僵死的进程数
第三/四行解释:
%Cpu0 : 3.7 us, 3.3 sy, 0.0 ni, 91.6 id, 1.3 wa, 0.0 hi, 0.0 si, 0.0 st
3.7%us:用户态进程占用第一/二个CPU时间百分比
3.3%sy:内核占用第一/二个CPU时间百分比
0.0%ni:renice值为负的任务的用户态进程的CPU时间百分比。nice是优先级的意思
91.6%id:第一/二个CPU空闲时间百分比
1.3%wa:等待I/O的CPU时间百分比
0.0%hi:第一/二个CPU硬中断时间百分比
0.0%si:第一/二个CPU软中断时间百分比
第五行解释:
KiB Mem : 8010688 total, 195456 free, 7432208 used, 383024 buff/cache
8010688k total:物理内存总数
195456k used: 使用的物理内存
7432208k free:空闲的物理内存
383024k cached:用作缓存的内存
第五行解释:
KiB Swap: 0 total, 0 free, 0 used. 331660 avail Mem
0k total:交换空间的总量
0k used: 使用的交换空间
0k free:空闲的交换空间
331660k cached:缓存的交换空间
最后一行:
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
PID:进程ID
USER:进程的所有者
PR:进程的优先级
NI:nice值
VIRT:占用的虚拟内存
RES:占用的物理内存
SHR:使用的共享内存
S:进行状态 S休眠 R运行 Z僵尸进程
%CPU:占用的CPU
%MEM:占用内存
TIME+: 占用CPU的时间的累加值
COMMAND:启动命令
10.2 uptime命令
1 | top - 23:59:34 up 141 days, 43 min, 1 user, load average: 0.11, 0.17, 0.18 |
第一行解释:
top - 23:59:34 up 141 days, 43 min, 1 user, load average: 0.11, 0.17, 0.18
23:59:34:系统当前时间
up 141 days, 43 min :系统开机到现在经过了2天
1 users:当前1用户在线
load average: 0.11, 0.17, 0.18:系统1分钟、5分钟、15分钟的CPU负载信息.
备注:load average后面三个数值的含义是最近1分钟、最近5分钟、最近15分钟系统的负载值。这个值的意义是,单位时间段内CPU活动进程数。如果你的机器为单核,那么只要这几个值均<1,代表系统就没有负载压力,如果你的机器为N核,那么必须是这几个值均<N才可认为系统没有负载压力。
10.3 w命令
1 | 00:05:53 up 141 days, 50 min, 1 user, load average: 0.14, 0.20, 0.20 |
第一行解释:
top - 23:59:34 up 141 days, 43 min, 1 user, load average: 0.11, 0.17, 0.18
23:59:34:系统当前时间
up 141 days, 43 min :系统开机到现在经过了2天
1 users:当前1用户在线
load average: 0.11, 0.17, 0.18:系统1分钟、5分钟、15分钟的CPU负载信息.
备注:load average后面三个数值的含义是最近1分钟、最近5分钟、最近15分钟系统的负载值。这个值的意义是,单位时间段内CPU活动进程数。如果你的机器为单核,那么只要这几个值均<1,代表系统就没有负载压力,如果你的机器为N核,那么必须是这几个值均<N才可认为系统没有负载压力。
第二行解释:
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
USER —登录的用户名
TTY —登录后系统分配的终端号
FROM—远程主机名,即从哪儿登录来的
LOGIN@—何时登录
IDLE—空闲了多长时间,表示用户闲置的时间。这是一个计时器,一旦用户执行任何操作,该计时器便会被重置
JCPU—和该终端(tty)连接的所有进程占用的时间,这个时间里并不包括过去的后台作业时间,但却包括当前正在运行的后台作业所占用的时间
PCPU—指当前进程(即在WHAT项中显示的进程)所占用的时间
WHAT—当前正在运行进程的命令行
10.4 vmstat命令
1 | procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- |
r:当前运行的进程数量,也就是当前有多少进程真正的分配到了CPU,这个值很重要,可以即刻看出机器压力,值超出CPU数量的时候就要着重关注了
b:当前阻塞的进程数量,值越高压力越大
swpd:虚拟内存已使用的大小,如果这个值不为0,则表示机器的物理内存已经不够使了,如果非程序内存泄漏,那就加内存吧
free:空闲的物理内存大小,单位byte,这里表示当前机器的物理内存还有202176byte(197M)可用,8G的内存得到了充分的利用
buff:用来存储目录里面有什么内容、权限等信息的缓存,
cache:用来记忆我们打开的文件,给文件做缓冲,提升了内存的使用效率,在快上又快了一步,神奇~
si:每秒从磁盘读入虚拟内存的大小,如果这个值大于0,表示物理内存不够用或者内存泄露了
so:每秒虚拟内存写入磁盘的大小,判断规则和si一样
bi:块设备每秒接收的块数量,这里的块设备是指系统上所有的磁盘和其他块设备,默认块大小是1024byte
bo:块设备每秒发送的块数量,例如我们读取文件,bo就要大于0。bi和bo一般都要接近0,不然就是IO过于频繁,需要调整
in:每秒CPU的中断次数,包括时间中断
cs:每秒上下文切换次数
us:用户CPU时间
sy:系统CPU时间
id:空闲 CPU时间,id + us + sy = 100
wa:等待IO时间
st:虚拟机偷取的CPU时间的百分比(具体是啥意思,还没搞懂,暂时不需要关注这个)
10.5 sar命令
10.6 free命令
10.7 df命令
10.8 du命令
10.9 iostat命令
10.10 iotop命令
10.10 CPU使用率
对单核CPU
以下四条中的任何一条命令都可以将CPU吃满
1 | cat /dev/zero > /dev/null |
对多核
使用循环或者管道实现
1 | 循环 |
10.11 内存使用率
内存使用率有点难搞,有人推荐使用stress 和lookbusy工具来实现,参见9.4和9.5
10.12 磁盘使用率
1 | dd if=/dev/zero of=loadfile bs=1M count=1024 # 输出 1024M 的 \0 到 loadfile |