夜黑风高的周末夜晚,正躲在书房追剧刘老根4,突然手机开始震个不停,心想难道是我的比特币要炸了吗?慌忙拿起手机的那一刻突然想起来我好像买不起比特币(心凉半截),原来是在公司群里被人艾特了,原来是S部门的某个Java服务出现了性能问题,找我这个Z部门的人帮忙看一下,描述是这样的:
白天的时候jvm涨的快,gc的几秒就完成了
到了晚上低峰期,jvm会涨的非常慢,但是一旦满了,就需要一两分钟时间进行gc,所以每隔一大段时间,会卡住一两分钟
一次GC需要一两分钟的时间,最快的时候也需要几秒钟,心里一紧,这是个大活啊,我们知道每一次GC都会引起STW,STW基本在毫秒级是正常的,他们最快也到了秒级,那就是如果平均十秒钟进行一次GC,每次3秒钟,那么一分钟就要消耗18秒的时间用于GC回收,服务时间只有可怜的43秒,秒算一下吞吐量就是42/60≈0.7,这个吞吐量简直太低了。既然说了GC的问题,那么我就只能先从GC日志入手了,对方突然告诉我没有gc日志,纳尼?没有GC日志那如何分析具体情况,通过GC日志排查问题的路子貌似走不通了,那就换一种思路,看一下JVM堆内存的分配情况,对方突然又告诉我堆大小设置了100G,哈哈…抓紧跑到厨房开了一罐冰镇雪花一饮而尽压一下任督二脉,然后让对方把JVM堆的详细信息以及启动时JVM配置发过来:
1 | Heap Usage: |
这个可以通过JVM的jmap -heap命令得到,详细操作就不做说明了,通过堆的信息,我做了几个假设:
- Eden区较大,每次Minor GC时待标记的对象较多
- Survivor区空间较小,Minor GC后无法容纳仍存活对象,导致对象过早的进入到老年代,致使老年代空间不足
- 老年代空间不足,导致频繁发生FGC
- 堆空间过大,每次FGC做标记时,待标记的对象较多
刚分析好,就又收到了JVM启动配置,如下:
1 | -XX:CICompilerCount=15 |
从启动配置上得出了Young和Old的比例是默认的1:2,以及Eden和Survivor的比例是默认的8:1:1,新生代使用的是Parallel Scoverage垃圾收集器,那么对应的老年代就是Parallel Old垃圾收集器(jdk1.8版本),并发线程是38,服务器是322G40C的配置,这些参数都没什么问题,从上面堆的信息能够看到在新生代中,Eden和Survivor的比例并不是按照8:1:1来分配的,Eden区很明显高于Survivor区太多,这是因为在实际运行过程中JVM对整体堆内存分配做了自适应,它认为太多的对象在第一次Minor GC的时候就会被回收,所以就加大了Eden区的大小,但是这种配置就会出现了一个问题:当某一次Minor GC时候,Eden区仍有一半的对象存活,但此时整个Young区的空间都被Eden区霸占了,Survivor区已经申请不到更多的内存,这就会造成很多存活的对象直接进入到老年代中,迅速占领老年代的空间,然后发生FGC。
简单问了一下S部门的同学为什么将堆设置到100G,给我的回答是:一开始是设置的20G,但是经常有人反馈服务响应较慢,所以就调整到了50G,结果运行一段时间后还被反馈响应较慢,然后就调到了100G,正准备调成150G呢,结果被告知来找我们帮忙。我推测是不是在设置为20G的时候出现了OOM,所以才想的提升堆的内存,然后他们告诉我并没有发生OOM,这也就是说其实堆内存在20G的时候是够用的,性能之所以拉跨,是因为分代内存设置的不合理,导致出现了过多的FGC,而FGC之后,堆又释放了很多空间,于是我推断大多数对象的存活周期都比较短,是因为Survivor区较小导致他们进入到了老年代,然后在FGC的时候被回收掉。
这么分析下来,证明了我上面所做的假设全部正确,既然问题出在堆空间分配上,我就重新来做一次分配吧:把堆最大内存设置为30G,并且通过-Xmx和-Xms让堆在初始化时就向系统申请30G的空间,然后通过-Xmn指定新生代的大小为18G,并且调整Eden和Survivor区的比例为2:1:1,让对象在Minor GC阶段就被回收掉,垃圾收集器由并行的Parallel修改为新生代使用ParNew、老年代使用CMS,完整的配置如下:
1 | -Xms30g |
重启服务之后配置生效,使用jmap检查下堆内存是否有按照我们设置的进行分配:
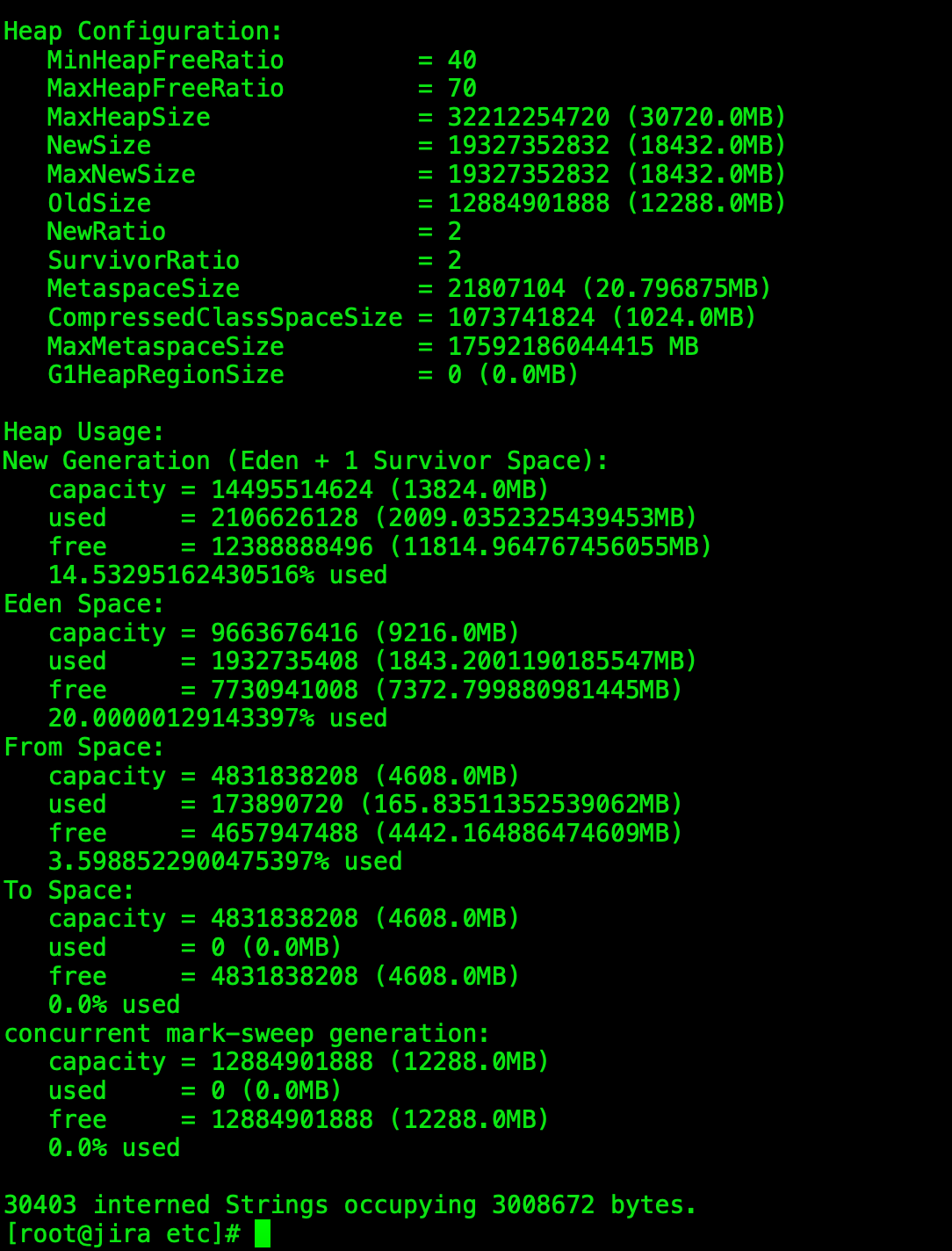
完美,说明我们的设置已经生效了,那么接下来就是监控GC的情况了,在服务运行了12个小时之后,捞出GC日志,这里贴一下最近的几条GC日志

GC日志告诉我们从37295到46560这9265秒(2.5h)内,均未发生FGC,并且YGC的时间也很好的控制在了毫秒级,虽然还是有点高,但毕竟我们使用的堆内存较大,这个量级已经算是还不错了。算下来每次进入到老年代的对象在几十~几千kb,虽然也挺多,但堆内存较大,还在容忍范围内。
既然看了GC,那我们也就顺道看一下当前的堆内存使用情况:
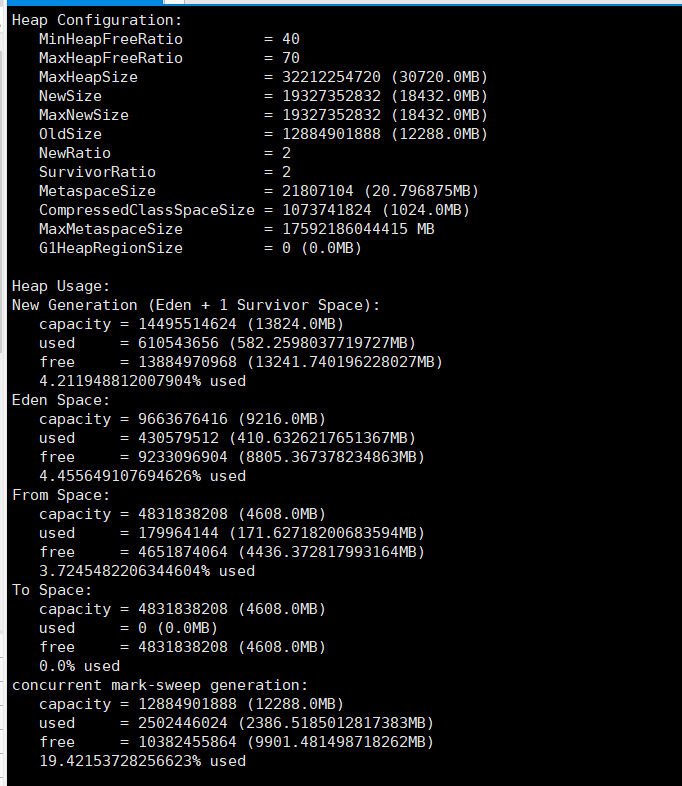
在没有发生FGC的情况下,老年代使用了19.4215%的空间,新生代的Eden区使用了4.4556%的空间,Survivor区使用了3.724548%,看样子还挺不错的。