领域
领域:表示正在处理的现实世界中复杂的业务逻辑和规则构成的问题域
领域模型:对现实世界真实业务的抽象描述,与任何技术都无关
子域:整个业务领域的一部分,与微服务划分的粒度有关,包括核心域、支撑子域、通用子域
- 核心域:核心业务,是一个有明确限界上下文的定义明确的业务领域模型,项目的核心业务体现,需重点打磨
- 支撑子域:支撑核心域,依据核心域内容进行“定制化”开发
- 通用子域:辅助核心域,拿来即用主义,不需要“定制化”
基于数据库建模(Database Modeling)
- 通过数据抽象系统关系
- 贫血模型模式
- 通过数据库字段映射仅属性getter和setter,无具体行为
- 相应行为通过Service实现
- 日积月累容易出现胖服务层和贫血
基于对象建模(Object Modeling)
- 通过面向对象方式抽象系统关系
- 最佳的领域建模方式(不考虑持久化的情况)
- 充血模型模式
- 不仅包含属性状态,还包括具体行为
- Service层逻辑变薄弱,模型丰富了行为
领域模型:
- 对具有某个边界的领域的一个抽象,反映了领域内业务需求的本质
- 具有边界性,只反映我们在领域内所关注的部分
- 只反映业务,和任何技术实现无关
- 不仅能反映领域内的一些实体概念,还能反映领域中的一些过程概念
- 确保整个软件的业务逻辑都在一个模型中,提升了软件的可维护性、业务可理解性以及可重用性
- 帮助开发人员平滑的将领域知识转化为软件构造
- 贯穿软件分析、设计、整个开发过程,领域专家、设计人员、开发人员通过领域模型进行交流,可以有效的防止需求走样
- 领域模型必须由领域专家、设计、开发人员共同建立,一起不断的深入和细化模型
- 用图、代码或文字描述的形式表达领域模型,使其可见化
- 能够快速响应需求变化的领域模型必须设计的足够精良且符合业务需求
实体(Entity)
- 一个由他的标识定义的对象称为实体
- 通常具有唯一id
- 能够被持久化
- 具有业务逻辑
- 对应现实世界的业务对象
- 一个持续抽象的生命,可以变化不同的形态和情形,但总有相同的标识
- 要防止设计成贫血模型
值对象(Value Object)
- 一个描述领域方面但没有概念标识符的的对象
- 用来表示临时的事物,可当作是实体的属性
- 没有特性标识,但能够表达领域中某类含义
- 一般不具有唯一id,由对象的属性描述,可以用来传递参数或对实体进行补充描述
- 作为实体属性的描述时,值对象也会被存储
- 对象不可变,所有属性均为只读,可以被复制或共享
- 本质上,值对象只是代表一个值
区别:
- 唯一标识:实体有;值对象没有
- 对象判断:实体只看唯一标识是否相等;值对象看全部属性是否相等
聚合及聚合根(Aggregate & Aggregate Root)
-
定义领域对象的所有权和边界的领域模型
-
聚合帮助简化模型对象间的关系
-
通过定义对象之间清晰的所属关系和边界来实现领域模型的内聚,且避免了错综复杂难以维护的对象关系网的形成
-
聚合是对领域模型的深化,能阐释领域模型内部对象之间的深层关联,聚合关系会直接映射到程序结构上
-
一个聚合是一组相关的被视为整体的对象
-
每个聚合都有一个根对象(聚合根实体),根实体对象可以聚合所有对象的引用,但从外部访问只能通过这个根对象
-
仅根实体能使用仓储库直接查询,根实体被删除后,聚合内部的对象级联删除
-
聚合有一个根和一个边界,根是聚合内的某个实体,边界定义了一个聚合内部有哪些实体或值对象
-
聚合内部的对象之间可以相互引用,根为内部对象的唯一引用
-
聚合根对外负责与外部对象打交道,对内负责维护自己的内部业务规则
-
聚合内部对象可以拥有对其他聚合根的引用
-
聚合内的所有对象都必须同聚合根一起被删除
工厂(factories)
- 用来封装创建一个复杂对象,将创建对象的细节隐藏起来
- 通过简单入参创建复杂的领域对象,最终传出一个根实体
仓储(repositories)
- 管理实体的集合
- 仅存储聚合的对象(因为domain是以聚合的概念来划分边界,聚合作为一个整体,共存亡)
- 仓储定义部分+仓储实现部分=仓储
- 领域模型中定义仓储的接口
- 基础设施层实现具体的仓库
- dao层方法粒度更细,更接近数据库;repository是一个独立的抽象,粒度略粗,接近领域
- 领域对象只依赖于repository
- 客户端调用领域对象,领域对象再调dao将数据持久化
服务(Service)
- 分派业务逻辑给领域对象进行处理,绝大部分的业务逻辑都由领域对象承载和实现
- Service与其他组件进行交互,包括:其他Service、领域对象、repository、dao
- 代码必须非常简洁,必须实现对领域底层组件的调用
- 服务对象名称应包含一个动词
- Service接口的传入/传出参数都应该是DTO
- 包含领域对象和DTO的转换以及事务
- 服务执行的操作涉及一个领域概念,这个领域概念通常不属于一个实体或者值对象
- 被执行的操作涉及到领域中其他的对象
- 操作是无状态的
domain事件
- 系统事件、应用事件、领域事件
- 领域事件触发点在领域模型中
- 作用是将领域对象从repository和Service的依赖中解脱出来,避免让领域对象对这些设施产生直接依赖
- 作法就是当领域对象的业务方法需要依赖到这些对象时,就发出一个事件,这个事件会被相应的领域对象监听到,并做出处理
- 实现领域模型对象状态的异步更新、外部系统接口的委托调用、通过事件派发机制实现系统集成
- 领域事件本身具有自我描述性,不仅可以表达系统发生了什么事情,还能够描述发生事件的动机
DTO(Data Transfer Object)
- 以粗粒度的数据结构减少网络通信并简化调用接口
架构层次
- 层
- 构成应用或服务的水平堆叠的一组逻辑上的组件
- 帮助区分完成不同任务的组件
- 提供一个最大化复用和可维护性的设计
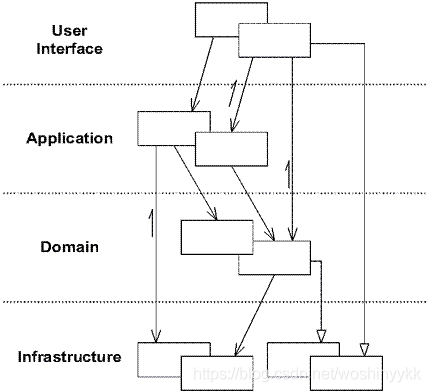
- User Interface
- 包含与其他系统/客户进行交互的接口与通信设施
- 该层包含web、service、rmi、rest等一种或多种通信接口
- 该层由facade、dto、assembler三类组件构成
- dto:以粗粒度的数据结构减少网络通信并简化接口调用
- facade:为远程客户端提供粗粒度的调用接口,本身不处理任何的业务逻辑,主要工作就是将一个用户请求委派给一个或多个service进行处理,同时借助assembler将service传入或传出的领域对象转为dto进行传输
- assembler:将领域对象与dto进行相互转换
- Application
- 主要组件就是service
- service的组织粒度和接口设计与传统的transaction script风格的service是一致的,但又有区别
- transaction script的核心是过程,通过过程的调用来组织业务逻辑,业务逻辑在服务层进行处理
- transaction script简单容易理解,面向过程设计,基础设施不会有技术的改变,业务逻辑很少变动
- transaction script不适合复杂的业务逻辑,事务之间的冗余代码会递增,应用架构容易出现“胖服务层”和“贫血的领域模型”,service层聚积越来越多的业务逻辑,导致可维护性和扩展性变差
- transaction script的业务逻辑主要在service中实现
- 领域模型属于面向对象设计,具备自己的属性行为和状态,领域对象之间可以通过聚合解决实际的业务应用
- 领域模型可复用、可维护、可扩展,可以采用合适的设计模型进行详细设计
- 领域模型需要设计人员有良好的抽象能力,相对复杂
- 领域模型的service层只负责协调并委派业务逻辑给相应的领域对象进行处理
- Domain
- 整个系统的核心层
- 该层维护一个使用面向对象技术实现的领域模型
- 该层实现大部分的业务逻辑,乃至全部的业务逻辑
- 该层包含entity、value object、domain event 和 repository等领域组件
- Infrastructure
- 为User Interface、Application、Domain三层提供支撑
- 提供所有的与平台、框架相关的实现
- 提供对象持久化的具体实现
领域模型的设计步骤
- 根据需求建立一个初步的领域模型,识别出一些明显的领域概念以及它们的关联性,关联可以暂时没有方向但是必须有关系(1:1, 1:n, n:m),可以使用文字或图精确的描述出每个领域概念的含义和包含的主要信息
- 分析主要的软件应用程序,识别出主要的应用层的类,分清应用层和领域层的职责
- 进一步分析领域模型,识别出实体、值对象、领域服务
- 分析关联性,通过对业务的深入分析以及各种软件设计原则及性能方面的权衡,明确关联的方向(新增或删除)
- ☆找出聚合边界和聚合根,需要借助平时的一些分析经验的积累才能找出正确的聚合根
- 为聚合根配备仓储,一般情况下一个聚合分配一个仓储,设计好仓储的接口
- 分析场景,确定设计的领域模型能够有效的解决业务需求
- 确定领域实体和值对象的创建方式,比如工厂或构造函数
- 尝试重构模型,寻找模型中不确定的地方,比如领域对象是从仓储获取还是通过聚合得到,聚合设计是否正确,性能如何等等
DDD特征
- 一个以pojo为基础的架构
- 支持使用DDD概念的业务领域模型的设计和实现
- 支持依赖注入和面向切面编程的开箱即用
- 整合单元测试框架
- 良好的集成其他javaee框架
领域模型分类
-
失血模型
- domain object中的属性只有getter/setter方法
- 所有的业务逻辑均由business object完成(又称transaction script)
-
贫血模型
- Service(Transaction script) —> DAO —> domain object
- domain object包含了不依赖于持久化的领域逻辑
- 依赖于持久化的领域逻辑被分离到service层
- domain logic 和 business logic
- domain logic只和这一个domain object的实例状态有关
- business logic可以和多个domain object的实例状态有关
- 将domain logic放到domain object之后,domain object仍独立于持久层之外,且仍是一个完备的、自包含的、不依赖于外部环境的领域对象
- 在service中执行与持久层相关的业务逻辑
- 各层单向依赖,结构清晰,易于实现和维护
- 设计简单易行,底层模式非常稳定
-
充血模型
- Service(Transaction script) —> domain object <—> DAO
- 与贫血模型的区别在于业务逻辑的划分
- 大部分业务逻辑都放在domain object中,包括持久化逻辑
- domain object中包含了domain logic 和 business logic
- Service层仅封装事务和少量逻辑,不和DAO层打交道
缺点
- DAO和domain相互依赖,会导致很多潜在问题
- Service层逻辑和domain层逻辑对于水平参差的设计和开发人员来说容易含混不清
- Service层需要对domain object的逻辑提供相应的事务,结果会导致Service层把所有的domain logic都重新定义一遍,最终把domain层实现的OO在Service层又变成了过程式
-
胀血模型
- domain object <—> DAO
- 去掉service层
- 在domain logic上封装事务
缺点
- 过多的service逻辑耦合到domain object中,会引起domain object模型的不稳定
- domain object暴露过多的信息给web层,可能会引起不必要的影响
比较
- 失血模型和胀血模型不推荐
- 推荐使用贫血模型